










Bước vào năm 2026, cuộc đua phát triển các Mô hình Ngôn ngữ Lớn (LLM) và Bất kỳ Data Engineer nào khi build dataset cho LLM cũng đều từng nếm mùi: code crawler chạy rất mượt ở quy mô nhỏ, nhưng cứ scale lên cào vài chục nghìn trang là y như rằng ăn block. Các hệ thống Anti-bot hiện đại (như Cloudflare hay DataDome) giờ đây bắt thóp IP rất nhanh, sẵn sàng ban cả một dải IP Datacenter chỉ trong vài giây nếu phát hiện lượng request bất thường.
Để giải quyết triệt để bài toán rate-limit và vượt qua các tường lửa gắt gao, kỹ thuật Web Scraping cho AI hiện nay bắt buộc phải chuyển dịch sang một lớp hạ tầng mới: Residential Proxy. Bằng cách định tuyến luồng cào dữ liệu qua hàng triệu IP dân dụng hợp pháp, các request của bạn sẽ nghiễm nhiên được hệ thống đích đánh giá là traffic người dùng thật.
Vậy Residential Proxy có cơ chế định tuyến cụ thể ra sao để qua mặt các hệ thống WAF khắt khe nhất? Và làm thế nào để thiết kế một Data Pipeline thu thập hàng Terabyte dữ liệu mà vẫn tuân thủ tuyệt đối các đạo luật bảo mật thông tin cá nhân mới nhất?
Bản chất hạ tầng Web Scraping cho AI: tại sao lại là Residential Proxy?
Để xây dựng một hệ thống thu thập dữ liệu quy mô lớn, việc hiểu rõ bản chất của hạ tầng mạng là bước đầu tiên và quan trọng nhất.
Khái niệm và cơ chế định tuyến (Routing Flow)
Residential Proxy (Proxy dân cư) là một máy chủ trung gian sử dụng địa chỉ IP thực được cấp phát bởi các Nhà cung cấp dịch vụ Internet (ISP như VNPT, Viettel, Comcast…) cho các thiết bị dân dụng thực tế (máy tính cá nhân, điện thoại thông minh kết nối Wi-Fi tại nhà). Vì sử dụng IP trực tiếp từ người dùng thực tế, mạng lưới này thường được cấu trúc theo dạng mạng ngang hàng (peer-to-peer).
Cơ chế định tuyến của Residential Proxy diễn ra như sau:
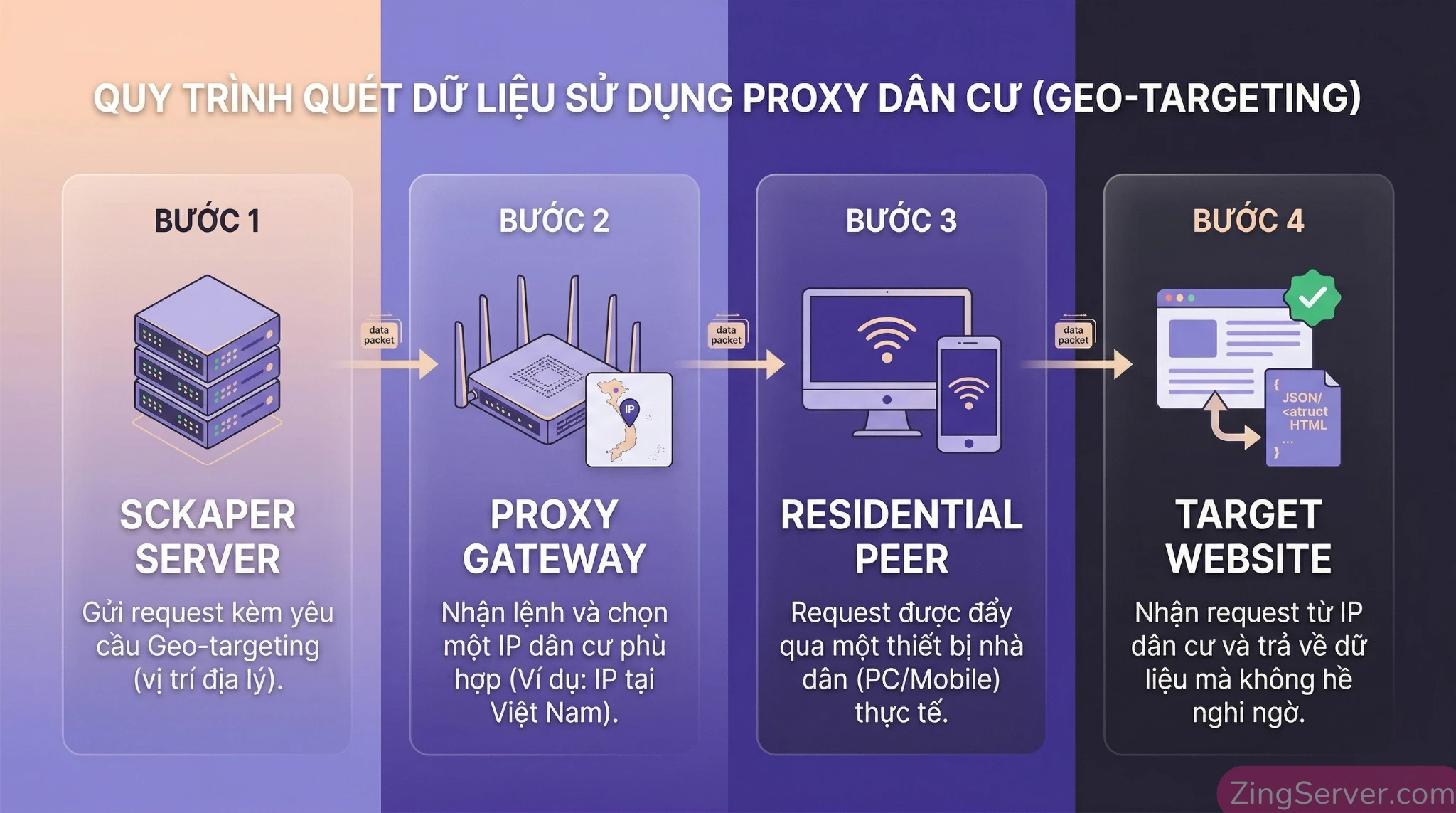
Khi hệ thống Web Scraping cho AI của bạn phát đi một yêu cầu truy cập (request), yêu cầu này không đi thẳng đến máy chủ đích. Thay vào đó, nó được định tuyến thông qua một thiết bị dân dụng đang hoạt động trong mạng lưới proxy. Thiết bị này sẽ chuyển tiếp yêu cầu đến trang web đích, nhận dữ liệu phản hồi (văn bản, hình ảnh công khai) và gửi trả về hệ thống của bạn.
Đối với hệ thống tường lửa (Firewall) của trang web nguồn, yêu cầu này trông giống hệt như một lượt truy cập từ kết nối mạng của một hộ gia đình bình thường (ví dụ: một người dùng ở Cầu Giấy, Hà Nội đang đọc tin tức), giúp che giấu danh tính và IP của máy chủ thu thập dữ liệu gốc.
Bảng so sánh các loại Proxy
Để tối ưu hóa chi phí và hiệu năng cho Data Pipeline, Data Engineer cần phân biệt rõ Residential Proxy với Datacenter Proxy cũng như các loại hình hạ tầng mạng khác trên thị trường:
| Tiêu chí | Datacenter Proxy | Residential Proxy (xoay vòng) | ISP Proxy (Static Residential) | Mobile Proxy (3G/4G/5G) |
| Nguồn gốc IP | Máy chủ đám mây, trung tâm dữ liệu (AWS, Google Cloud). | Thiết bị dân dụng thực (PC, laptop) qua mạng Wi-Fi tại nhà. | Trung tâm dữ liệu nhưng được đăng ký dưới tên các ISP hợp pháp. | Thiết bị di động thực kết nối qua mạng viễn thông. |
| Mức độ tin cậy | Thấp (Dễ bị hệ thống Anti-bot phát hiện là IP nhân tạo). | Cao (Trông giống hệt người dùng cá nhân hợp pháp). | Cao (Được hệ thống đánh giá uy tín như IP dân cư). | Cao nhất (Độ tin cậy tuyệt đối do cơ chế CGNAT chia sẻ IP). |
| Tốc độ & độ trễ | Cực nhanh (nhanh hơn 3-4 lần so với dân cư), độ trễ cực thấp. | Trung bình (Phụ thuộc vào chất lượng mạng Wi-Fi của hộ gia đình). | Cực nhanh (Tốc độ và độ ổn định ngang ngửa Datacenter). | Chậm nhất (Độ trễ trung bình rất cao do sóng viễn thông). |
| Nguy cơ bị chặn | Rất cao (Tỷ lệ thành công chỉ đạt 40-60% với web bảo mật). | Rất thấp (Tỷ lệ thành công đạt 95-99% trên trang bảo mật). | Thấp (Tỷ lệ thành công 85-95%). | Rất khó bị chặn, nhưng vẫn có rủi ro nếu hành vi bất thường. |
| Chi phí | Rẻ nhất (Tính theo số lượng IP cố định). | Đắt (Tính phí theo dung lượng băng thông tiêu thụ tính bằng GB). | Rất đắt (Chi phí đàm phán mua IP tĩnh từ ISP truyền thống rất cao). | Cực kỳ đắt (Tính theo GB hoặc thuê thiết bị cổng vật lý). |
| Ứng dụng chính | Web không bảo vệ, các tác vụ cần tốc độ cao, độ trễ thấp. | Web Scraping cho AI quy mô lớn, vượt Rate-Limit tự nhiên. | Quản lý tài khoản mạng xã hội dài hạn, mua sắm giới hạn. | Tự động hóa mạng xã hội, kiểm thử ứng dụng di động. |

Phân loại cấu trúc mạng Proxy cho Data Engineer
Trong lĩnh vực Web Scraping cho AI, chiến lược thu thập dữ liệu quyết định cách bạn cấu hình Residential Proxy. Thông thường, có hai kịch bản kỹ thuật chính:
Rotating Proxy (xoay vòng IP tự động)
Hệ thống mạng lưới sẽ tự động thay đổi địa chỉ IP dân cư sau mỗi yêu cầu (request) hoặc sau một chu kỳ mili-giây rất ngắn.
- Ứng dụng thực tiễn: Đây là cấu hình xương sống để thu thập dữ liệu công khai khối lượng khổng lồ (high-volume scraping). Khi bạn cần tải về hàng triệu bài báo, tạp chí khoa học mở hoặc bình luận diễn đàn, việc xoay IP liên tục giúp phân tán lưu lượng truy cập. Nhờ đó, bạn có thể vượt qua các cơ chế giới hạn tần suất (Rate Limiting) của trang web, né tránh việc một IP bị đưa vào danh sách đen do gửi quá nhiều yêu cầu, và hoàn toàn minh bạch khi thu thập dữ liệu từ các trang kết quả tìm kiếm (SERP).
Sticky Session (duy trì IP / gắn bó phiên)
Cấu hình này cho phép giữ nguyên một địa chỉ IP dân cư trong một khoảng thời gian cụ thể (ví dụ: 10, 15, hoặc 30 phút) xuyên suốt một phiên làm việc.
- Ứng dụng thực tiễn: Được sử dụng khi Kỹ sư Dữ liệu cần duy trì bối cảnh (Context) của luồng thao tác. Ví dụ: Nếu luồng thu thập yêu cầu tự động điền các form nhiều bước, tương tác với giỏ hàng thương mại điện tử (để lấy dữ liệu giá), hoặc theo dõi dữ liệu thay đổi theo thời gian thực mà việc đổi IP giữa chừng sẽ làm máy chủ nguồn nghi ngờ và lập tức ngắt kết nối (drop connection).
Tại sao Data Pipeline năm 2026 bắt buộc cần Residential Proxy?
Phương pháp thu thập dữ liệu bằng IP trung tâm dữ liệu (Datacenter) đang ngày càng thất bại trước các bức tường lửa (WAF) và hệ thống an ninh mạng hiện đại (như Cloudflare, DataDome). Đối với Web Scraping cho AI, Residential Proxy giải quyết ba bài toán cốt lõi:
- Mức độ uy tín (Trust Score) cực cao: Các hệ thống Anti-bot hiện nay không chỉ đếm số lượng request mà còn chấm điểm uy tín của IP. Thay vì trông giống một cỗ máy tự động tấn công từ đám mây, lưu lượng từ Residential Proxy mô phỏng chính xác dấu vân tay mạng của một người dùng thực.
- Tránh bị cấm dải IP hàng loạt (Subnet Bans): Các IP Datacenter thường được tạo ra hàng loạt và có chung dải mạng (Subnet). Nếu hệ thống bảo mật phát hiện một IP là bot, chúng dễ dàng đánh dấu đỏ và chặn toàn bộ dải IP đó. Ngược lại, hàng triệu IP dân cư được phân tán độc lập ngẫu nhiên trên toàn cầu, khiến thuật toán bảo mật của trang web không dám cấm diện rộng vì sợ chặn nhầm người dùng hợp pháp.
- Hỗ trợ tính đa dạng địa lý (Geo-Targeting): Để huấn luyện một mô hình ngôn ngữ lớn hiểu được văn hóa địa phương, AI cần dữ liệu mang tính bản địa. Kỹ sư có thể cấu hình Residential Proxy để mượn IP tại một thành phố cụ thể (VD: IP tại TP.HCM hoặc IP tại Tokyo) để vượt qua các rào cản nội dung bị chặn theo vùng (Geo-blocking), đảm bảo bộ dữ liệu AI thu được có tính đại diện và không bị thiên lệch (bias).
Ranh giới pháp lý 2026: tuân thủ Luật 91/2025/QH15
Việc sở hữu hạ tầng thu thập dữ liệu mạnh mẽ phải luôn đi kèm với sự tuân thủ pháp luật khắt khe. Kể từ ngày 01/01/2026, Luật Bảo vệ dữ liệu cá nhân (Luật số 91/2025/QH15) và Nghị định 356/2025/NĐ-CP đã thiết lập những lằn ranh đỏ cực kỳ nghiêm ngặt tại Việt Nam.
Mức phạt răn đe khổng lồ đối với vi phạm dữ liệu
Các doanh nghiệp AI cần đặc biệt lưu ý đến các chế tài xử phạt mới:
- Vi phạm chung: Mức phạt tiền hành chính tối đa đối với tổ chức lên đến 3 tỷ VNĐ.
- Chuyển dữ liệu xuyên biên giới trái phép: Đây là rủi ro lớn nhất cho hạ tầng Cloud AI. Nếu doanh nghiệp cấu hình sai Data Pipeline dẫn đến việc chuyển dữ liệu cá nhân nhạy cảm ra máy chủ nước ngoài trái phép, mức phạt có thể lên tới 5% tổng doanh thu của năm trước liền kề.
- Mua bán dữ liệu trái phép: Phạt tiền tối đa bằng 10 lần khoản thu có được từ hành vi vi phạm.
Ma trận thu thập dữ liệu cá nhân (PII) trong Web Scraping cho AI
Nhiều người lầm tưởng luật mới cấm tuyệt đối việc thu thập Họ tên, Email, Số điện thoại (PII cơ bản). Về mặt pháp lý, điều này là không chính xác. Doanh nghiệp hoàn toàn ĐƯỢC PHÉP thu thập nếu đáp ứng 1 trong 6 cơ sở pháp lý (chủ yếu là có Sự đồng ý (Consent) của người dùng).
Tuy nhiên, đối với đặc thù của Web Scraping cho AI, bài toán lại rẽ sang một hướng khác:
Khi bot của bạn rà soát hàng triệu trang blog, tin tức hay diễn đàn công khai, bạn không thể gửi biểu mẫu xin Sự đồng ý đến từng cá nhân có thông tin xuất hiện trên các trang đó. Việc thu thập PII đại trà này làm mất đi cơ sở pháp lý hợp lệ.
Hơn nữa, nếu đưa dữ liệu thô này vào huấn luyện LLM, mô hình sẽ gặp rủi ro Hiệu ứng ghi nhớ (Memorization Effect). Mô hình có thể vô tình xuất ra số điện thoại thực của ai đó khi người dùng cuối đặt câu hỏi (Inference-time), dẫn đến thảm họa rò rỉ quyền riêng tư. Do đó, để tuân thủ pháp luật và đạo đức, mọi Data Pipeline xây dựng bộ dữ liệu AI bắt buộc phải chủ động lọc bỏ (Scrub) mọi PII ngay từ khâu tiền xử lý.
Thiết kế Pipeline thu thập dữ liệu tuân thủ đạo đức
Để biến các điều khoản luật khô khan thành quy trình kỹ thuật thực chiến, Data Engineer cần thiết lập một kiến trúc hệ thống kiểm soát rủi ro tự động.
Nâng cấp PII Scrubber bằng công nghệ NER (NLP)
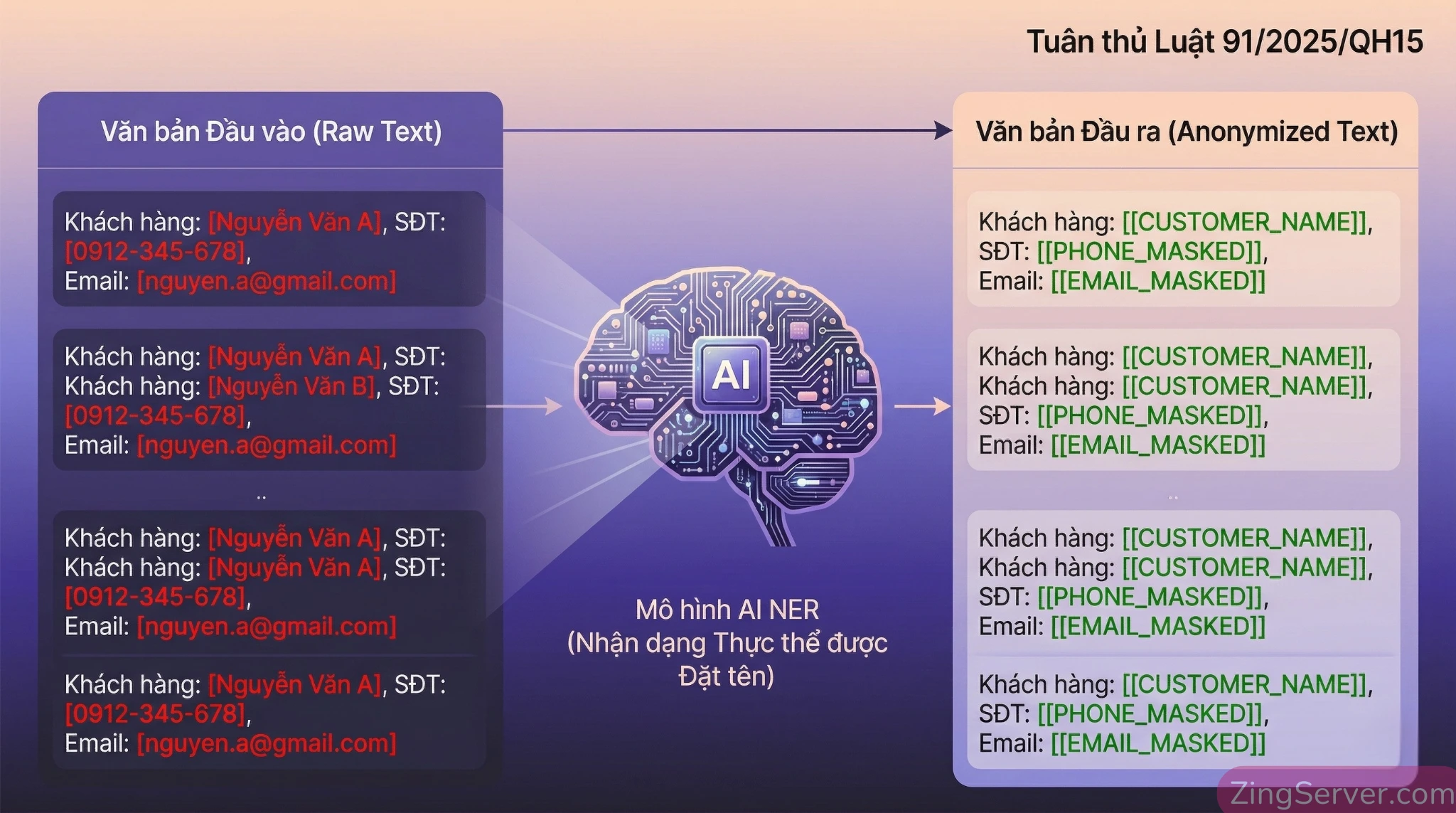
Để lọc PII khỏi văn bản thu thập được, trước đây các kỹ sư thường dùng Biểu thức chính quy (Regex). Tuy nhiên, Regex trong năm 2026 đã bị xem là lỗi thời do nó hoạt động dựa trên các khuôn mẫu cố định (pattern), hoàn toàn không nhận biết được ngữ cảnh. Regex dễ dàng bỏ sót các số điện thoại viết bằng chữ hoặc tạo ra vô số Dương tính giả (False Positives), ví dụ nhận diện nhầm một mã số tài liệu thành số Căn cước công dân.
Tiêu chuẩn kiến trúc hiện đại bắt buộc sử dụng các mô hình Nhận dạng thực thể có tên (NER – Named Entity Recognition) dựa trên Xử lý ngôn ngữ tự nhiên (NLP). NER (như mô hình GLiNER) có khả năng đọc và hiểu ngữ cảnh của câu văn. Nó nhận diện chính xác PII trong các đoạn văn bản lộn xộn, phi cấu trúc (Unstructured Data), sau đó thay thế tự động bằng các nhãn an toàn (ví dụ: [PERSON_NAME_REMOVED]). Kỹ thuật này giúp khử định danh hoàn toàn mà vẫn bảo toàn được cấu trúc ngữ nghĩa để AI học tập một cách hiệu quả.
Quy định DPIA & chính sách ân hạn cho Startup AI
Bất kỳ hoạt động thu thập và xử lý dữ liệu quy mô nào cũng yêu cầu doanh nghiệp phải lập Hồ sơ đánh giá tác động xử lý dữ liệu cá nhân (DPIA) và nộp cho Cục An ninh mạng trong vòng 60 ngày.
Tuy nhiên, Luật 91/2025/QH15 mang đến một đặc quyền rất lớn cho giới công nghệ: Doanh nghiệp vi mô, doanh nghiệp nhỏ và Startup đổi mới sáng tạo được hưởng thời gian ân hạn lên đến 5 năm để tuân thủ quy định nộp DPIA này.
Lưu ý quan trọng: Đặc quyền ân hạn 5 năm sẽ BỊ TƯỚC BỎ ngay lập tức nếu Startup AI của bạn thực hiện thu thập và xử lý dữ liệu trên quy mô lớn (từ 100.000 chủ thể dữ liệu trở lên), hoặc trực tiếp xử lý dữ liệu nhạy cảm.
Cam kết SLA xóa dữ liệu (phản hồi 72 giờ & Best Practice xóa mềm)
Pháp luật quy định chặt chẽ về Giới hạn lưu trữ và Quyền xóa dữ liệu. Khi người dùng gửi yêu cầu xóa, hệ thống của bạn phải phản hồi (tiếp nhận) chậm nhất trong 2 ngày làm việc và hoàn thành việc xử lý (xóa) trong tối đa 20 – 30 ngày (tùy thuộc vào vai trò là Bên kiểm soát hay Bên xử lý dữ liệu).
Vậy hệ thống AI có bắt buộc phải xóa sạch vĩnh viễn (Hard-delete) dữ liệu ngay trong tích tắc khi có yêu cầu không? Câu trả lời là Không.
Về mặt giải pháp kỹ thuật, Kỹ sư Dữ liệu luôn áp dụng cơ chế Soft-delete (Xóa mềm) trong 30 ngày làm Best Practice. Khi có lệnh xóa, tài khoản/dữ liệu sẽ được đổi trạng thái sang “deleted” (đã xóa mềm) và lưu trữ ẩn trong 30 ngày để đề phòng rủi ro thao tác nhầm hoặc lỗi hệ thống. Chỉ sau khi khoảng thời gian ân hạn 30 ngày kết thúc, một tiến trình tự động (cron job) mới kích hoạt việc Hard-delete vĩnh viễn khỏi toàn bộ kiến trúc Data Lake và các Node huấn luyện.
- Xem thêm: Thuê VPS GPU hay VPS CPU để chạy mô hình AI cục bộ (Local LLM) an toàn? (2026) • ZingServer
Tiêu chuẩn Robots.txt AI 2026 và khoảng trống tuân thủ (Data Compliance Gap)
Để đảm bảo tính minh bạch khi thực hiện Web Scraping cho AI, Data Engineer không chỉ dựa vào proxy mà còn phải tuân thủ các giao thức kiểm soát môi trường mạng mới nhất.
Tiêu chuẩn giao tiếp AI mới: llms.txt và Named User-Agent
Trong năm 2026, tệp robots.txt truyền thống đã được bổ sung thêm sức mạnh bởi sáng kiến llms.txt. Tệp này được định dạng bằng Markdown, giúp tóm tắt nội dung website và trỏ AI đến các trang tài liệu chuẩn xác nhất, ngăn chặn crawler thu thập phải rác dữ liệu.
Đồng thời, Liên minh Giảm thiểu Cào dữ liệu Trái phép (MUSA) cũng đưa ra tiêu chuẩn bắt buộc: Các Data Pipeline phải khai báo rõ ràng danh tính thông qua Named User-Agent (ví dụ: GPTBot, ClaudeBot, hoặc YourCompany-AIBot/1.0). Chủ website hiện nay áp dụng Content Signals Policy để phân biệt rõ lưu lượng truy cập: Đâu là bot lập chỉ mục tìm kiếm thông thường (Search), đâu là bot thu thập dữ liệu để huấn luyện (Train/Crawl). Việc khai báo User-Agent minh bạch giúp chủ website có quyền chủ động điều phối và cấp quyền truy cập công bằng.
Tuân thủ đạo đức có làm AI “kém thông minh” đi không?
Rất nhiều CTO lo ngại rằng: Việc chặn thu thập dữ liệu theo robots.txt và làm sạch PII bằng mô hình NER sẽ tạo ra Khoảng trống tuân thủ dữ liệu (Data Compliance Gap DCG), khiến mô hình LLM bị thiếu hụt kiến thức.
Tuy nhiên, các nghiên cứu thực nghiệm được công bố trên arXiv đầu năm 2026 đã chứng minh điều ngược lại: Việc tuân thủ đạo đức KHÔNG làm giảm kiến thức tổng quát của AI.
Mức chênh lệch hiệu suất (DCG) đối với các bài kiểm tra kiến thức chung gần như bằng 0%. Đối với thách thức mất bối cảnh ngôn ngữ do xóa PII, các kỹ sư AI hàng đầu đã chuyển sang sử dụng kỹ thuật Tinh chỉnh chỉ thị (Instruction-Based Tuning). Thay vì cắt bỏ thô bạo (Redaction), LLM được huấn luyện thành các Contextual Privacy Protection Learners tự học cách nhận biết đâu là thông tin nhạy cảm để tạo ra câu trả lời bảo mật mà không làm suy giảm hiệu suất lý luận ngôn ngữ.
Tiêu chí chọn nhà cung cấp Residential Proxy minh bạch (Ethical Sourcing)
Việc sử dụng mạng lưới proxy bị đánh cắp (botnet) qua các ứng dụng VPN miễn phí mờ ám sẽ phá hủy hoàn toàn nỗ lực tuân thủ pháp lý của doanh nghiệp AI. Hợp tác với các Ethical Proxy (Proxy đạo đức) là tiêu chí bắt buộc trong quy trình thẩm định.
Một nhà cung cấp hạ tầng Residential Proxy uy tín phải đáp ứng các tiêu chuẩn cốt lõi sau:
- Nguồn gốc IP tự nguyện và minh bạch (Explicit Opt-in): Chủ thiết bị (người dùng cuối) phải được thông báo rõ ràng, đồng ý cho mượn IP và được đền bù thỏa đáng bằng tiện ích hoặc tài chính.
- Quyền ngắt kết nối (2-click Opt-out): Chủ sở hữu IP có quyền hủy tham gia mạng lưới bất kỳ lúc nào một cách dễ dàng.
- Giám sát tài nguyên thiết bị: Hệ thống proxy chỉ định tuyến lưu lượng khi thiết bị gốc có tài nguyên rảnh rỗi, tuyệt đối không làm cạn kiệt pin hoặc ngốn băng thông cá nhân.
- Không thu thập dữ liệu người dùng cuối: Nhà cung cấp chỉ mượn cổng mạng, tuyệt đối không cài cắm mã độc để theo dõi hay đánh cắp dữ liệu của thiết bị cho mượn (đảm bảo chuẩn GDPR).
- Quy trình KYC nghiêm ngặt: Đơn vị bán Proxy phải thẩm định danh tính doanh nghiệp mua rất chặt chẽ, ngăn chặn tội phạm mạng lợi dụng hạ tầng để tấn công từ chối dịch vụ (DDoS) hay gian lận tài chính.

- Xem thêm: Mua Proxy Socks5 Việt Nam • ZingServer
Kết luận
Sự tiến hóa vũ bão của Trí tuệ Nhân tạo tạo ra một cơn khát dữ liệu vô tận. Trong cuộc đua đó, Web Scraping cho AI kết hợp cùng hạ tầng Residential Proxy đã chứng minh đây là bộ đôi công nghệ không thể thay thế. Chúng giúp Data Engineer tháo gỡ triệt để các rào cản Anti-bot tự nhiên, phân phối tải truy cập mượt mà và mang về các kho ngữ liệu đa ngôn ngữ, đa văn hóa chất lượng cao.
Tuy nhiên, trong một kỷ nguyên mà Luật Bảo vệ dữ liệu cá nhân (91/2025/QH15) sẵn sàng giáng những đòn phạt hàng tỷ đồng, sức mạnh công nghệ bắt buộc phải đồng hành cùng sự minh bạch và đạo đức. Bằng cách thiết lập nguồn IP tự nguyện (Ethical Sourcing), tích hợp mô hình NER NLP tinh vi để khử định danh PII, và tôn trọng tuyệt đối các tiêu chuẩn giao tiếp AI mới, doanh nghiệp của bạn hoàn toàn có thể xây dựng những siêu trí tuệ LLM xuất chúng mà vẫn an toàn tuyệt đối trên mọi hành lang pháp lý.
Tài liệu tham khảo
- Large Language Models Can Be Contextual Privacy Protection Learners – ACL Anthology
- Comparing Best NER Models For PII Identification
- Can Performant LLMs Be Ethical? Quantifying the Impact of Web Crawling Opt-Outs
- New AI web standards and scraping trends in 2026: rethinking robots.txt – DEV Community
- Robots.txt in the AI Environment: Ensuring Clarity, Trust, and Responsible Access – MUSA
- Web Scraping API Report 2025 – Proxyway
- Proxy Industry: Data Reports 2026





