










Hãy tưởng tượng một kịch bản không hiếm gặp: Hệ thống đang gặp bug nghiêm trọng, và một Senior Developer vô tư copy toàn bộ file log chứa đầy thông tin định danh khách hàng (PII) kèm theo một đoạn source code chìa khóa của công ty, rồi dán thẳng vào khung chat của ChatGPT hay Claude để nhờ debug. Ở một diễn biến khác, đội Sales đẩy nguyên file Excel báo cáo tài chính quý 4 chưa công bố lên một public AI tool để tóm tắt cho nhanh.
Sự tiện lợi của các API đám mây (Cloud AI API) đang trở thành cơn ác mộng bảo mật đối với các CTO và AI Engineer. Tài sản trí tuệ (IP) bị phơi bày, hóa đơn API token tăng phi mã theo từng tháng, và nguy hiểm nhất là những rủi ro vi phạm pháp lý treo lơ lửng trên đầu doanh nghiệp.
Câu hỏi đặt ra là: Làm sao để cấp cho nhân viên một hệ thống AI thông minh có khả năng truy xuất hàng vạn tài liệu nội bộ, nhưng không một byte dữ liệu nào được phép lọt ra ngoài mạng lưới công ty? Giải pháp triệt để và an toàn nhất hiện nay chính là triển khai RAG trên VPS GPU (Local Retrieval-Augmented Generation). Vậy làm thế nào để setup một kiến trúc Local RAG chuẩn production, đáp ứng bài toán security khắt khe nhưng vẫn đảm bảo latency thấp cho hàng trăm người dùng?
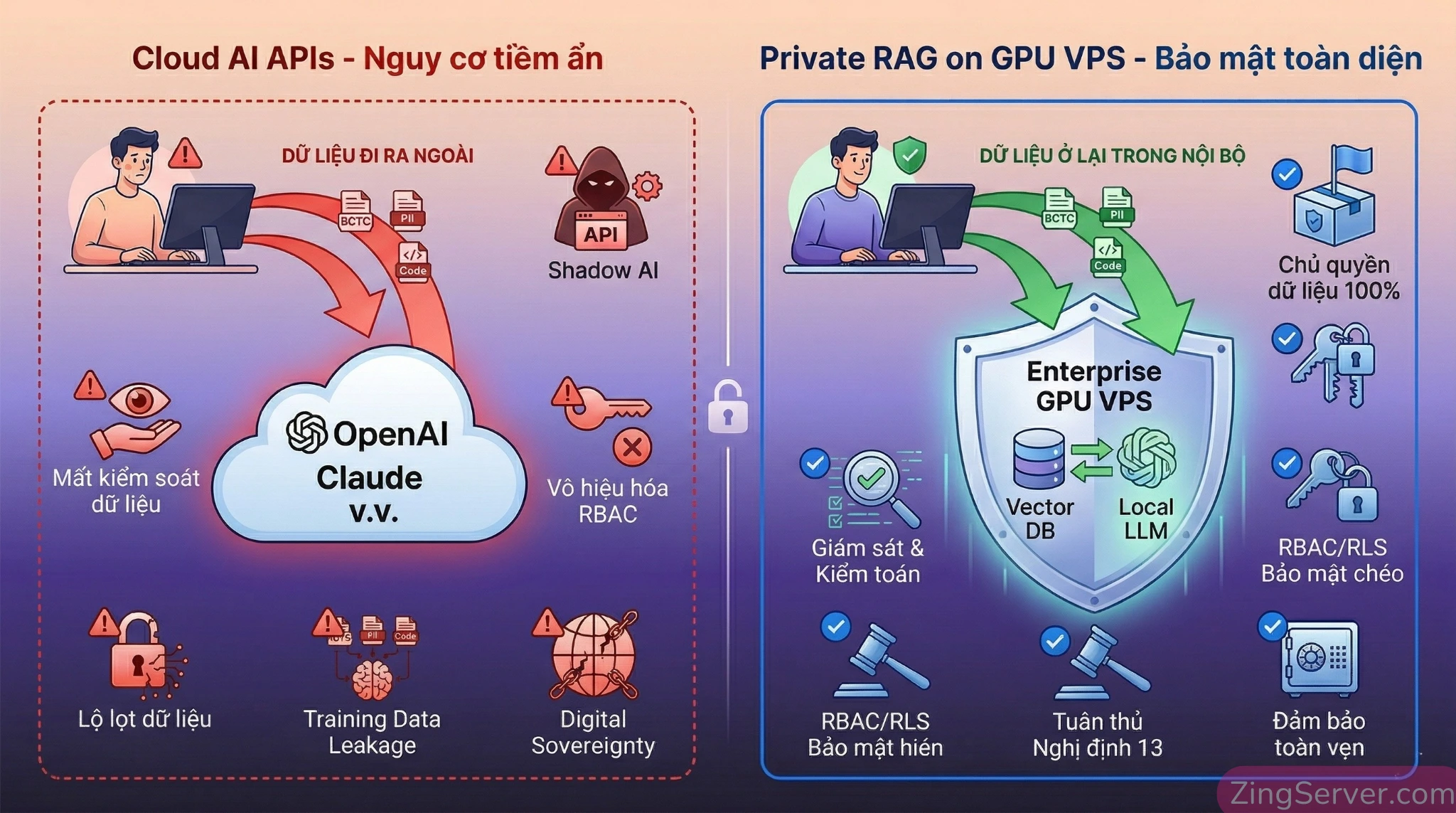
Tại sao doanh nghiệp cần cai nghiện Cloud AI API?
Trước khi đi sâu vào các dòng lệnh setup hạ tầng, chúng ta cần nhìn thẳng vào những nỗi đau thực tế và rủi ro chí mạng mà các giải pháp Public Cloud AI đang gây ra.
Nỗi ám ảnh rò rỉ dữ liệu và bài toán tuân thủ Nghị định 13/2023/NĐ-CP
Khi bạn gọi API của OpenAI hay Anthropic, dữ liệu nội bộ buộc phải rời khỏi hệ thống mạng nội bộ và đi qua máy chủ của bên thứ ba. Theo Báo cáo Thales Data Threat Report 2025, việc mất chủ quyền dữ liệu (Digital Sovereignty) mang đến những rủi ro cực kỳ nghiêm trọng:
- Vi phạm quy định chuyển dữ liệu ra nước ngoài: Tại Việt Nam, Nghị định 13/2023/NĐ-CP xếp thông tin tài chính, lịch sử giao dịch và PII vào nhóm dữ liệu cá nhân nhạy cảm. Việc gửi các dữ liệu này lên API nước ngoài được coi là hành vi chuyển dữ liệu xuyên biên giới. Nếu doanh nghiệp không lập Hồ sơ đánh giá tác động chuyển dữ liệu gửi Bộ Công an trong vòng 60 ngày, đây là một vi phạm pháp luật rành rành.
- Training Data Leakage (Rò rỉ dữ liệu huấn luyện): Các mô hình public có thể âm thầm học thông tin từ prompt. Kẻ tấn công có thể sử dụng kỹ thuật Prompt Injection hoặc Extraction attacks để lừa AI nôn ra báo cáo tài chính hoặc PII của doanh nghiệp bạn cho một người dùng hoàn toàn xa lạ.
- Shadow AI và Hệ sinh thái bên thứ ba: Những vụ rò rỉ chấn động từ các ứng dụng AI bên thứ 3 (như vụ lộ hàng triệu log chat, API key từ OmniGPT hay DeepSeek đầu năm 2025) chứng minh rằng: Đưa dữ liệu cho bên thứ ba xử lý là bạn đang giao phó sinh mệnh bảo mật của công ty cho người khác.
Thảm họa vô hiệu hóa kiểm soát truy cập (Broken RBAC)
Các hệ thống lưu trữ truyền thống bảo vệ dữ liệu bằng cơ chế phân quyền Role-Based Access Control (RBAC). Nhưng khi toàn bộ tài liệu được nhét chung vào một Public LLM để làm RAG đơn giản, mô hình AI không hề hiểu ranh giới phân quyền. Một nhân viên thực tập hoàn toàn có thể vô tình truy vấn và lấy được các phân tích tài chính vốn chỉ dành cho cấp C-Level.
Kiến trúc Local RAG giải quyết triệt để vấn đề này: Việc xử lý nhúng (embedding), cơ sở dữ liệu vector và suy luận LLM (inference) được chạy trên máy chủ VPS GPU hoàn toàn cách ly với internet (air-gapped). Dữ liệu không bao giờ rời khỏi hạ tầng CNTT, giải quyết ngay lập tức rào cản tuân thủ quyền riêng tư và loại bỏ hoàn toàn nguy cơ LLM học lỏm dữ liệu để fine-tune.
Kiến trúc Local RAG Stack thực chiến cho Enterprise
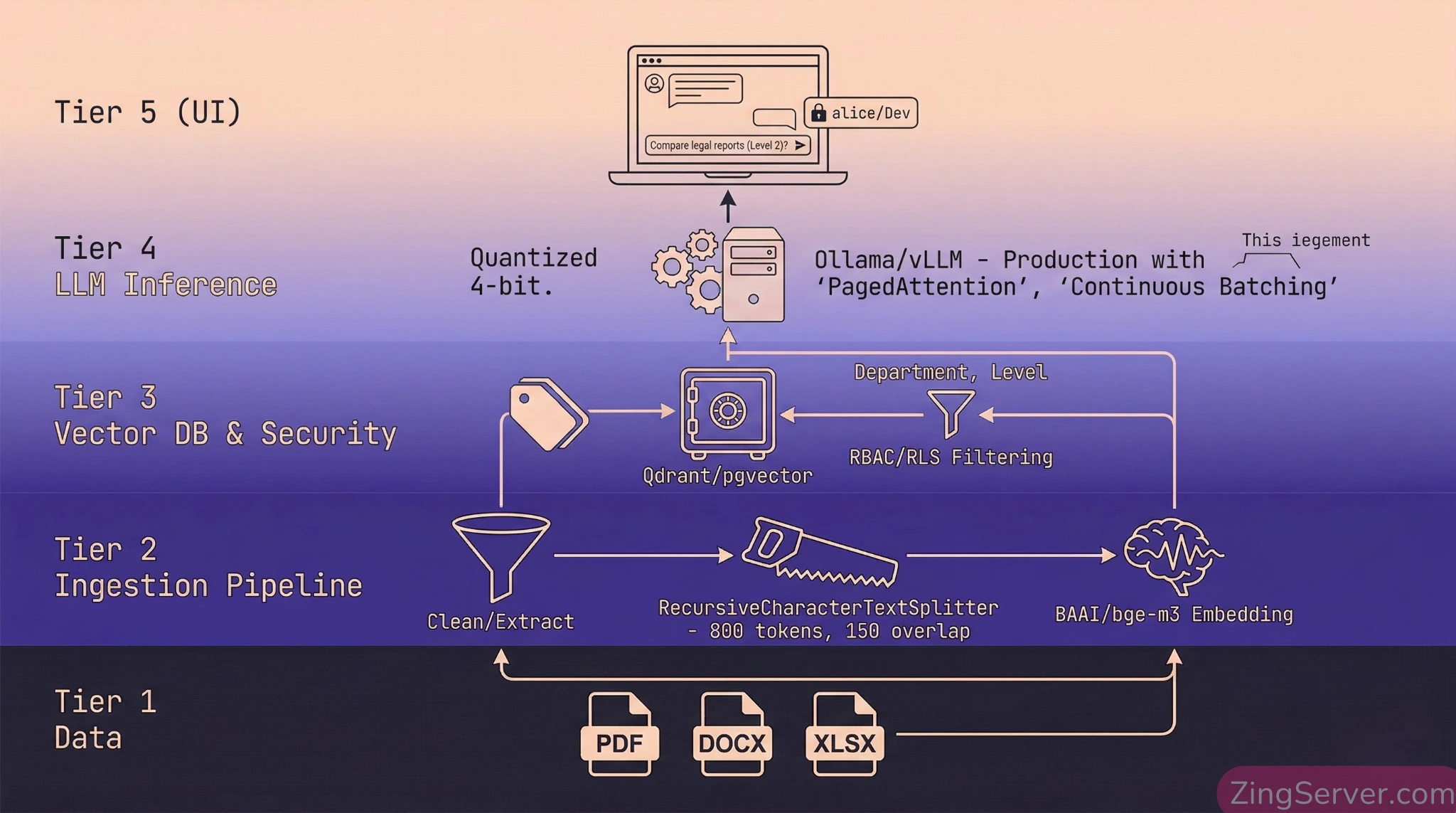
Để phục vụ cho cấp độ Enterprise, kiến trúc không thể dừng ở mức tải model về và chạy. Bạn cần một stack đảm bảo thông lượng cao (Throughput), độ trễ thấp (Latency) và khả năng phân quyền khắt khe.
LLM Engine: Lựa chọn giữa Ollama (PoC) và vLLM (Production)
Động cơ suy luận (Inference Engine) là trái tim của hệ thống.
- Ollama (Dành cho R&D và Single-user): Rất lý tưởng để thiết lập nhanh nguyên mẫu (PoC) nhờ khả năng tự động nhận diện phần cứng. Tuy nhiên, Ollama xử lý các request đồng thời bằng cách đưa vào hàng đợi (queue). Nếu có 30 người dùng cùng truy vấn, người cuối cùng sẽ phải đợi rất lâu. Ollama giống như một chiếc xe thể thao: chạy rất nhanh nhưng không chở được nhiều người.
- vLLM (Tiêu chuẩn cho Production): Khi scale lên multi-user, vLLM là bắt buộc. Sức mạnh của vLLM nằm ở thuật toán PagedAttention quản lý bộ nhớ KV cache như bộ nhớ ảo của hệ điều hành, giúp giảm lượng VRAM lãng phí từ 60-80% xuống dưới 4%. Kết hợp với Continuous Batching (chèn ngay request mới vào xử lý khi request cũ vừa sinh xong một token), vLLM có thể duy trì thông lượng hàng nghìn token/giây.
- Cập nhật thời sự: Với bản cập nhật Model Runner V2 (MRV2) ra mắt tháng 3/2026, vLLM đã tích hợp đồ thị Piecewise CUDA và cơ chế lập lịch bất đồng bộ zero-bubble (triệt tiêu thời gian chết của GPU), đồng thời có khả năng tải trước (prefetching) để che giấu hoàn toàn độ trễ tải trọng lượng mô hình.
Vector Database: Bịt kín rò rỉ chéo với Qdrant và pgvector
Để chặn đứng việc nhân sự phòng Dev đọc được tài liệu phòng HR, việc phân quyền phải được thực hiện ngay tại bước Truy xuất (Retrieval).
- Qdrant (RBAC & Payload Filtering): Khi nạp tài liệu, bạn gắn siêu dữ liệu (Payload) như
{"department": "HR"}. Lúc truy vấn, backend ép buộc chèn thêm điều kiện Lọc:Filter(must=[FieldCondition(key="department", match=MatchValue(value="Dev"))]). Qdrant sẽ tự động gạt bỏ các vector của phòng HR ra khỏi kết quả. Ở quy mô lớn, tính năng Tenant Index của Qdrant giúp nhóm các dữ liệu cùng phòng ban lại gần nhau trên ổ cứng, tăng tốc độ quét cực kỳ hiệu quả. - pgvector (Row-Level Security RLS): Nếu hệ thống dùng PostgreSQL, pgvector cho phép áp dụng RLS thẳng vào tầng kernel của database. Bạn định nghĩa policy
USING (department_id = current_setting('app.current_department')). Dù code backend RAG có bị lỗi, database vẫn từ chối quyền đọc ở mức thấp nhất, đảm bảo an toàn tuyệt đối.
Chiến lược Chunking và Embedding chuẩn bài
- Chunking (Băm văn bản): Đừng bao giờ cắt văn bản theo số ký tự cố định (fixed-size), điều này sẽ băm nát ngữ nghĩa của một đoạn văn. Hãy dùng
RecursiveCharacterTextSplittercủa LangChain. Thuật toán này chia nhỏ đệ quy, ưu tiên giữ các khối logic lớn (đoạn văn) trọn vẹn, và chỉ cắt xuống cấp độ câu/từ khi vượt quá giới hạn token. - Embedding Model:
BAAI/bge-m3là vũ khí tối thượng hiện nay. Nó hỗ trợ hơn 100 ngôn ngữ (bao gồm tiếng Việt xuất sắc), chiều dài context lên tới 8192 tokens. Đặc biệt, nó tích hợp 3 cơ chế trong 1 (Dense Retrieval, Sparse/Lexical Weight, Multi-Vector ColBERT) chỉ trong một lần tính toán, tiêu tốn cực ít VRAM và thậm chí có thể chạy tốt trên CPU.
4 bước triển khai RAG trên VPS GPU tối ưu hiệu năng và bảo mật
Dưới đây là roadmap thực chiến để các kỹ sư hệ thống dựng lên một cỗ máy AI nội bộ bất khả xâm phạm.
Bước 1: Sizing GPU VRAM thực tế đập tan lầm tưởng
Nhiều doanh nghiệp sợ build Local AI vì nghĩ cần mua cụm H100 giá chục tỷ. Thực tế, công nghệ lượng tử hóa 4-bit (như GGUF Q4_K_M hoặc AWQ) đã thay đổi cuộc chơi.
- Model 7B – 8B (Llama 3 8B, Qwen 2.5 7B): Trọng số 4-bit chỉ chiếm khoảng 4.3 GB – 4.6 GB. Một chiếc VPS GPU với card 8GB VRAM là hoàn toàn đủ để chứa model, để lại khoảng 3.5 GB cho KV Cache (xử lý thoải mái context từ 2.000 – 4.000 tokens).
- Model 14B: Trọng số 4-bit tốn khoảng 6-8 GB VRAM. Khuyến nghị sử dụng VPS GPU cấu hình 12GB – 16GB VRAM để tránh bị tràn bộ nhớ (OOM).
- Model 32B – 35B (Qwen 2.5 32B): Bản thân trọng số 4-bit đã ngốn khoảng 22 GB. Để chạy RAG nhồi nhiều ngữ cảnh, bạn cần cấp phát VPS từ 24GB VRAM (ngữ cảnh ngắn) đến 32GB – 40GB VRAM (cấu hình tối ưu).

Để hiểu sâu hơn về bài toán đánh đổi giữa hiệu năng và chi phí phần cứng, mời bạn tham khảo bài phân tích chuyên sâu: Thuê VPS GPU hay VPS CPU để chạy mô hình AI cục bộ (Local LLM) an toàn? (2026)
Bước 2: Security Hardening cô lập mạng và mã hóa ổ đĩa
Khi triển khai RAG trên VPS GPU, nếu không cô lập mạng chuẩn chỉ, server của bạn sẽ nhanh chóng biến thành mỏ đào coin hoặc bị chiếm đoạt GPU (Shadow Inference).
- Chống lỗ hổng Docker UFW Bypass: Bật UFW là chưa đủ, vì Docker thao tác thẳng vào
iptablesvà xuyên thủng UFW. Bạn BẮT BUỘC phải bind các container của vLLM và Vector DB vào giao diện loopback nội bộ:127.0.0.1(không dùng0.0.0.0). - Đường hầm SSL/TLS: Tuyệt đối không dùng HTTP trần. Sử dụng Nginx làm reverse proxy để mã hóa (HTTPS) mọi API giao tiếp nội bộ.
- Mã hóa phân vùng (Encryption at Rest): Tài liệu lưu trong Vector DB không được để plain-text trên ổ cứng. Sử dụng LUKS2 với chuẩn hàm dẫn xuất khóa Argon2id và AES-XTS. Để giải quyết bài toán tự động mở khóa khi reboot server (unattended boot) mà không lưu plaintext key, hãy triển khai khuôn khổ Clevis kết hợp chính sách TPM 2.0 hoặc máy chủ mạng Tang (NBDE).
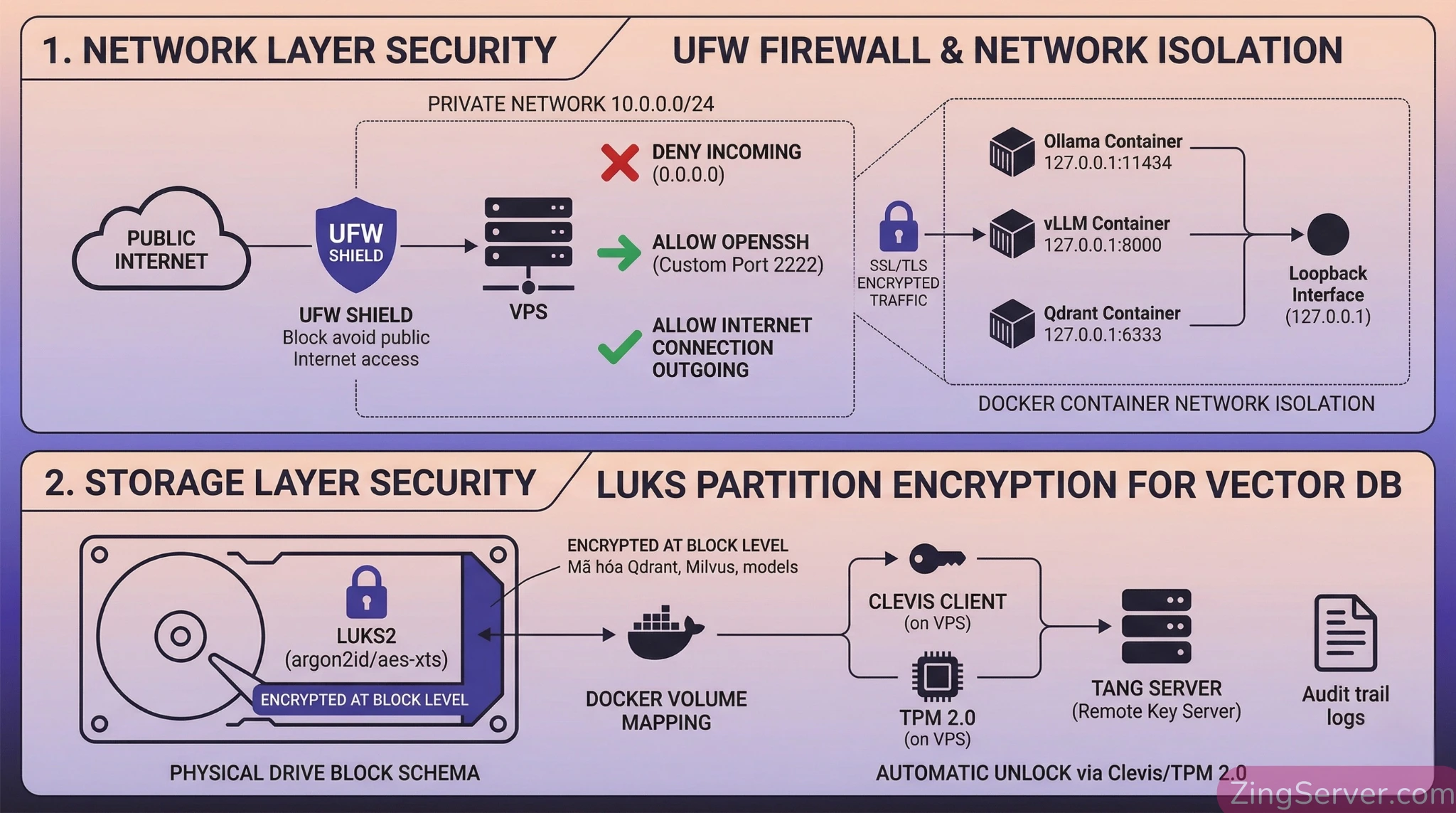
Để hệ thống đạt mức bảo mật toàn diện từ trong ra ngoài, các CTO nên kết hợp mã hóa ổ đĩa với chiến lược Nâng cấp bảo mật VPS 2026: Tích hợp Zero Trust thay thế phương pháp cũ, đảm bảo không một ai có thể truy cập hệ thống nếu không được xác thực liên tục.
Bước 3: Build Pipeline Ingestion nội bộ
Xây dựng một Data Pipeline (bằng Python) chạy ngầm:
- Sử dụng thư viện
UnstructuredhoặcPyPDF2để trích xuất văn bản từ hệ thống Sharepoint/Drive nội bộ. - Dùng
RecursiveCharacterTextSplittercắt văn bản thành các khối logic. - Nhúng dữ liệu bằng
BAAI/bge-m3và đẩy vào Qdrant/pgvector, nhớ gắn kèm các tag định danh phòng ban (Department) để phục vụ cho RLS/RBAC sau này.
Bước 4: Expose API nội bộ và triển khai UI
Không bao giờ để Frontend chọc thẳng vào API của LLM.
- Backend (FastAPI): Dựng một lớp Middleware xác thực user bằng JWT. Khi user gọi API, FastAPI kiểm tra Role, tự động chèn filter phân quyền xuống Vector DB để rút trích đúng tài liệu, sau đó mới đóng gói thành prompt gửi sang vLLM.
- Trong trường hợp hệ thống AI của bạn (như AI Agent) cần kết nối an toàn với các API bên thứ ba ở ngoài internet, đừng quên cấu hình luồng mạng bảo mật, bạn có thể xem chi tiết tại bài viết: Tại sao lập trình viên AI nên mua Proxy Socks5 để tối ưu và bảo mật kết nối API?
- Giao diện (Open WebUI / AnythingLLM): Sử dụng các nền tảng UI mã nguồn mở này để cung cấp trải nghiệm giống hệt ChatGPT cho nhân viên. Chúng hỗ trợ quản lý lịch sử chat, chia sẻ workspace biệt lập và không bao giờ gửi telemetry ra bên ngoài.
Tối ưu độ chính xác với Two-Stage Retrieval (Reranking)
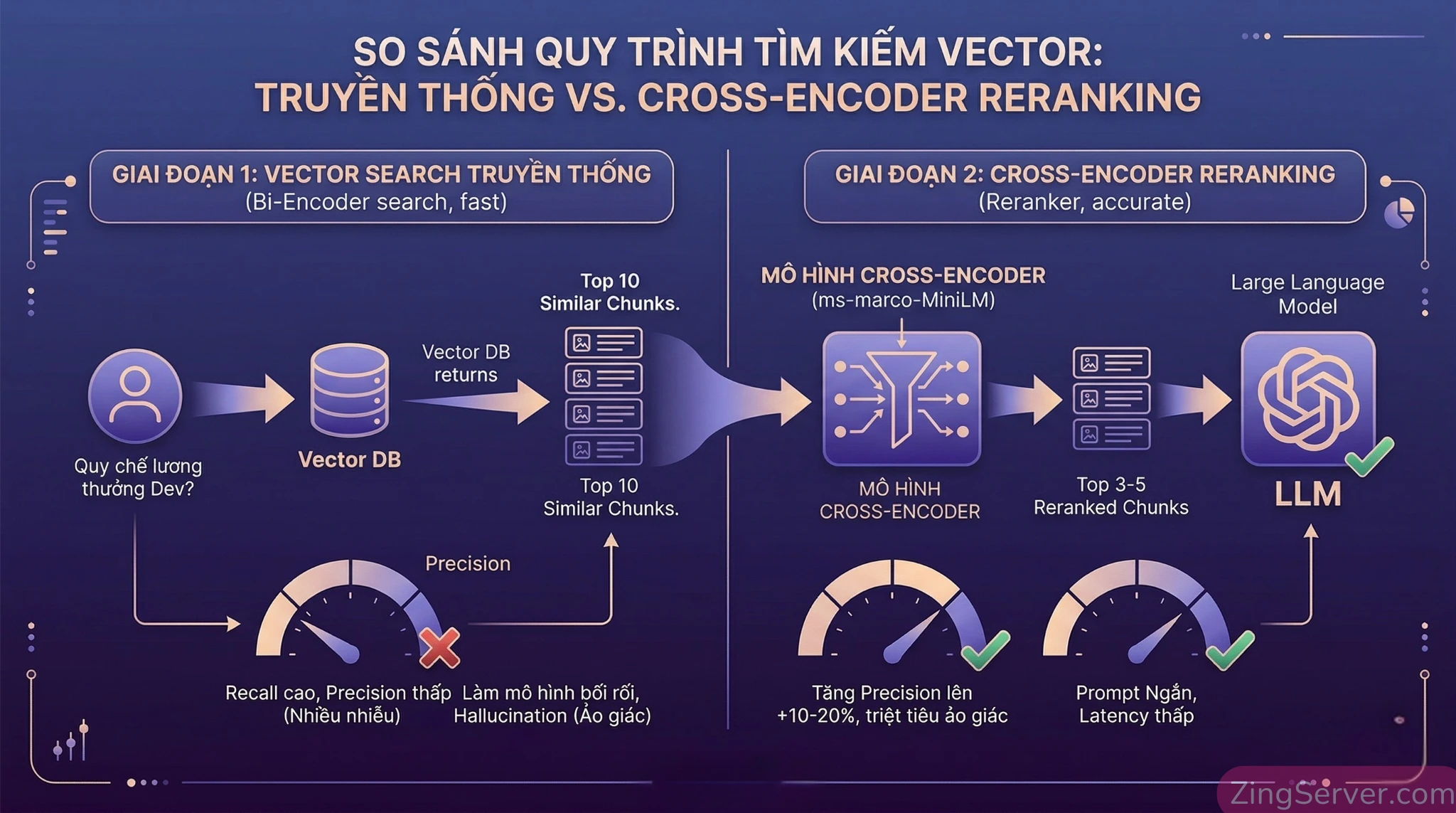
Điểm yếu chí mạng của Vector Search thông thường là bài toán Nhiễu (Noise). Bi-encoder có thể truy xuất ra 10 tài liệu na ná nhau về không gian toán học, nhưng thực chất chỉ có 2 tài liệu chứa câu trả lời. Nhồi cả 10 tài liệu này vào LLM sẽ gây lãng phí token, tăng độ trễ và làm mô hình bị bối rối, dẫn đến sinh ra ảo giác (Hallucination).
Giải pháp cho Enterprise là kỹ thuật Two-Stage Retrieval (Xếp hạng lại):
- Giai đoạn 1 (Recall): Dùng Bi-encoder (nhanh, rẻ) quét Vector DB để lấy ra Top 30-50 tài liệu ứng viên.
- Giai đoạn 2 (Precision): Đưa 30 tài liệu này qua một mô hình Cross-Encoder (như
ms-marco-MiniLMhoặc BGE-Reranker). Mô hình này sẽ chấm điểm trực tiếp mối quan hệ ngữ nghĩa giữa câu hỏi cụ thể và từng tài liệu. Hệ thống chỉ lấy Top 3 – 5 tài liệu điểm cao nhất đưa cho LLM.
Theo các benchmark thực tế, kỹ thuật này dù tốn thêm 100-200ms độ trễ nhưng giúp tăng độ chính xác của kết quả lên 10% đến 20%, triệt tiêu hoàn toàn lượng nhiễu văn bản và khắc phục dứt điểm căn bệnh ảo giác của AI.
Câu hỏi thường gặp (FAQ)
1. Cần tối thiểu bao nhiêu VRAM để chạy mượt hệ thống Local RAG?
Không cần đến H100 giá hàng chục tỷ. Nhờ công nghệ lượng tử hóa 4-bit (GGUF/AWQ), model 8B chỉ ngốn ~4.5GB VRAM. Bạn chỉ cần VPS GPU có card 8GB VRAM là dư sức xử lý. Với model 14B cần card 12-16GB, và model lớn 32B cần từ 24GB – 32GB VRAM.
2. Việc triển khai RAG trên VPS GPU có giải quyết được bài toán tuân thủ Nghị định 13/2023/NĐ-CP không?
Đáp ứng tuyệt đối 100%. Mọi luồng xử lý (Embedding, Vector DB, LLM Inference) đều bị cô lập trong mạng nội bộ (air-gapped). Dữ liệu không bao giờ bị chuyển xuyên biên giới hay lọt ra public internet, loại trừ hoàn toàn nguy cơ rò rỉ hoặc bị AI bên thứ 3 lấy làm data training.
3. Tại sao nên dùng vLLM thay vì Ollama cho môi trường Production?
Ollama rất dễ cài nhưng xử lý truy vấn theo dạng xếp hàng tuần tự, chỉ hợp làm PoC cho 1-2 user. vLLM sử dụng công nghệ PagedAttention và Continuous Batching, cho phép xử lý song song hàng chục request cùng lúc, đẩy throughput lên cao gấp hàng chục lần mà không bị thắt cổ chai.
4. Làm sao để ngăn nhân viên phòng Dev dùng AI truy xuất được tài liệu lương của phòng HR?
Chặn đứng ngay tại bước truy xuất của Vector DB. Hãy sử dụng tính năng Payload Filtering + RBAC của Qdrant, hoặc thiết lập Row-Level Security (RLS) trên pgvector. Backend sẽ tự động gạt bỏ các tài liệu không đúng thẩm quyền trước khi gửi context cho LLM đọc.
5. Tại sao hệ thống RAG đôi khi vẫn sinh ra ảo giác (Hallucination) và cách khắc phục?
Do Vector DB tìm theo độ tương đồng không gian (semantic) nên vẫn lôi lên nhiều tài liệu nhiễu, khiến LLM bị bối rối. Khắc phục bằng Two-Stage Retrieval (Reranking): Bổ sung một mô hình Cross-encoder (như ms-marco-MiniLM) để chấm điểm và lọc lại các tài liệu một cách khắt khe trước khi nạp vào Prompt, giúp tăng độ chính xác lên 20%.
Kết luận
Việc xây dựng AI không còn là cuộc chơi độc quyền của các tập đoàn nghìn tỷ. Triển khai kiến trúc Local RAG đang trở thành tiêu chuẩn bắt buộc (Blueprint) cho các doanh nghiệp muốn khai phóng sức mạnh tri thức nội bộ mà không phải hy sinh quyền riêng tư, an ninh mạng hay lo sợ các quy định pháp lý.
Bằng cách tận dụng sức mạnh linh hoạt của GPU VPS, sự bứt phá thông lượng của động cơ vLLM, và cơ chế bảo vệ rò rỉ chéo khắt khe của Qdrant/pgvector, bạn đã có thể xây dựng một cỗ máy AI mạnh mẽ như ChatGPT, nhưng an toàn tuyệt đối sau cánh cửa tường lửa.
Nếu bạn đã sẵn sàng bắt tay vào triển khai thực tế với các model đang hot nhất hiện nay, hãy xem ngay hướng dẫn từng bước: Thuê VPS GPU chạy AI: Setup DeepSeek & Llama 3.3 bảo mật.





