










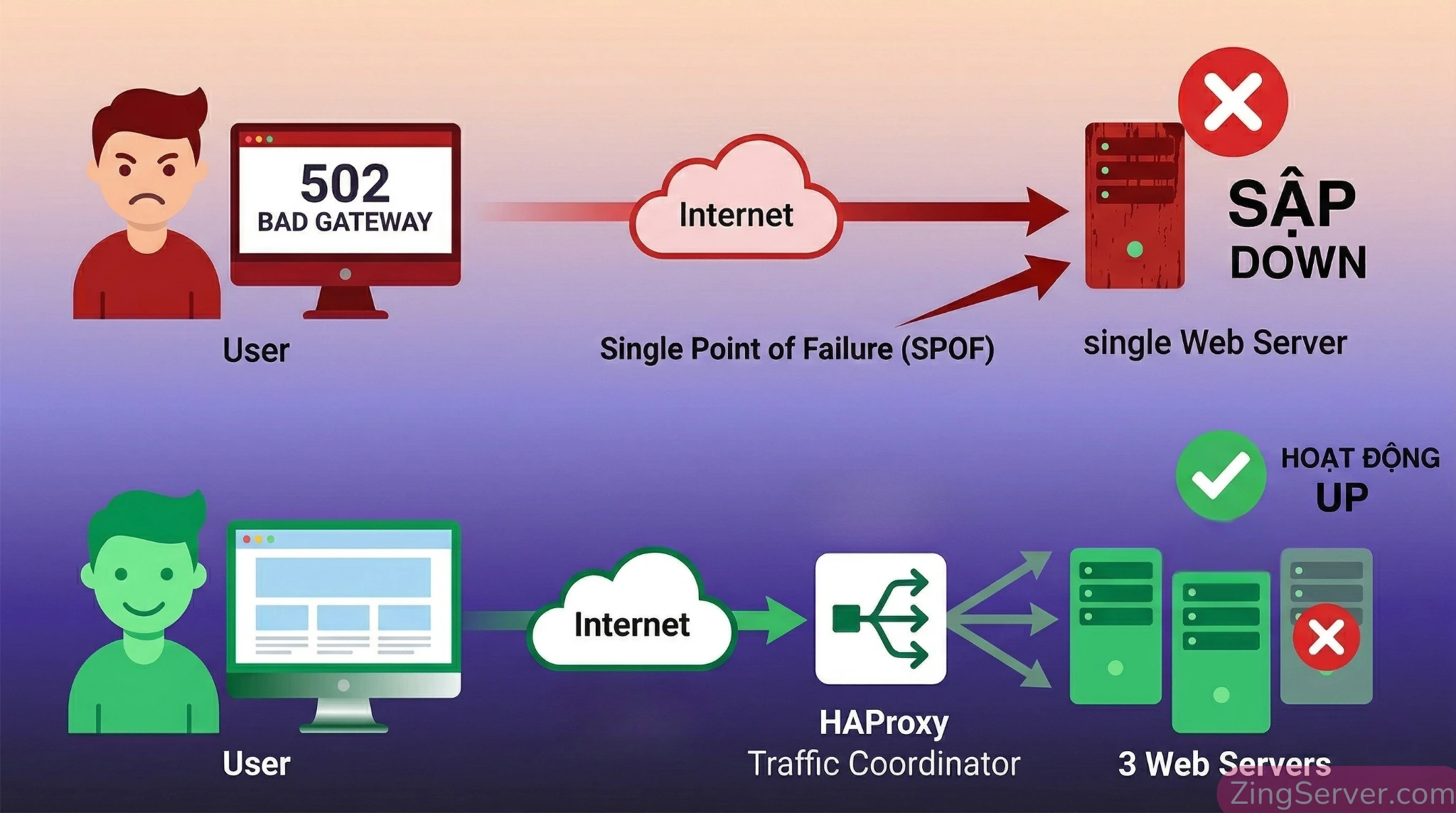
Đồng hồ hệ thống điểm 0h00, chiến dịch Flash Sale siêu sale cuối năm chính thức kích hoạt. Email blast vừa được bắn đi cho 500.000 khách hàng, các luồng Facebook Ads đang tiêu hao ngân sách liên tục. Đội Marketing đang hân hoan chờ dashboard nhảy số chốt đơn thì bất ngờ sự cố xảy ra. Màn hình xoay vòng vô tận, trình duyệt của người dùng đồng loạt trả về lỗi 502 Bad Gateway hoặc Database Connection Error. Server đã chính thức ngừng hoạt động.
Hàng trăm triệu đồng ngân sách Marketing đổ sông đổ biển chỉ vì lượng request dồn dập vào một máy chủ duy nhất gây cạn kiệt tài nguyên. Đây chính là cơn ác mộng mang tên Single Point of Failure (SPOF) mà bất kỳ developer hay kỹ sư mạng nào cũng từng ám ảnh. Để hệ thống hoạt động ổn định trước những đợt lưu lượng traffic đột biến, việc nâng cấp RAM hay CPU cho một server đơn lẻ (Scale-up) là không bao giờ đủ, bạn bắt buộc phải phân tán luồng truy cập sang nhiều node xử lý.
Đó chính xác là thời điểm mà việc cấu hình Load Balancer HAProxy trở thành giải pháp cốt lõi. Làm thế nào để điều phối hàng trăm nghìn connection cùng lúc mà không bỏ lỡ một giỏ hàng nào của khách? Hệ thống của bạn đã thực sự được tối ưu từ tầng ứng dụng xuống tận nhân Kernel chưa? Hãy cùng đi sâu vào từng dòng lệnh thực chiến ngay dưới đây.
Ám ảnh mang tên Single Point of Failure (SPOF) và bài toán Scale hệ thống
Single Point of Failure (Điểm đơn lỗi) là một thành phần trong hệ thống mà nếu nó gặp sự cố, toàn bộ kiến trúc sẽ ngừng hoạt động. Trong các hệ thống web truyền thống, nếu luồng mạng chỉ phụ thuộc vào một máy chủ web hoặc một database duy nhất (đặc biệt khi chưa tối ưu database VPS Linux), đó chính là một SPOF nghiêm trọng.
HAProxy đóng vai trò như một nhà điều phối giao thông xuất sắc, giải quyết bài toán SPOF ở cả hai cấp độ:
- Bảo vệ máy chủ ứng dụng (Backend Servers): Thay vì dồn traffic vào một máy chủ, HAProxy phân tán lưu lượng tới một pool gồm nhiều node backend (Load Balancing). Nó liên tục thực hiện các bài kiểm tra sức khỏe (Health Checks). Nếu một node mất kết nối, HAProxy ngay lập tức cách ly node đó, chuyển hướng request sang các node khỏe mạnh còn lại. Khi node lỗi phục hồi, nó tự động được đưa lại vào vòng luân chuyển.
- Ngăn bản thân HAProxy trở thành SPOF: Nếu chỉ chạy HAProxy trên một máy chủ, chính nó lại là điểm lỗi mới. Để khắc phục, các hệ thống Production luôn triển khai đa máy chủ (Redundancy) kết hợp với công cụ tạo IP ảo (như Keepalived). Nếu node HAProxy Master ngừng hoạt động, IP ảo lập tức được chuyển giao sang node Backup, đảm bảo dịch vụ không gián đoạn.
Tại sao các kỹ sư mạng lại tin dùng HAProxy? (bí mật hiệu năng)
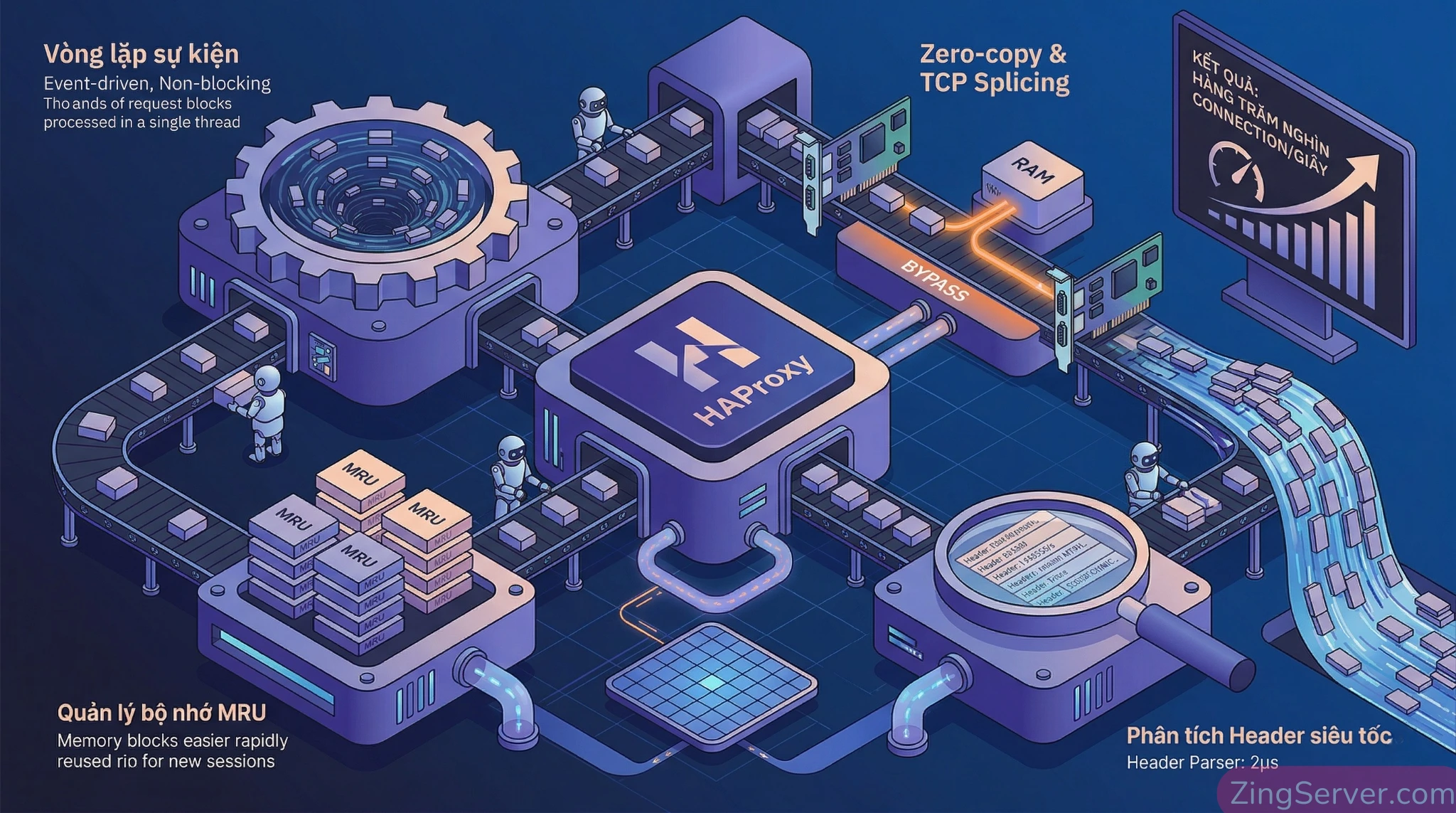
Trên thị trường có rất nhiều công cụ cân bằng tải, nhưng HAProxy luôn là tiêu chuẩn vàng của các tổ chức lớn như GitHub hay Roblox (xử lý hơn 100 triệu người dùng/ngày). Sức mạnh này đến từ kiến trúc phần mềm tối ưu đến từng micro-giây:
- Kiến trúc hướng sự kiện (Event-driven, Non-blocking): HAProxy không tạo ra hàng ngàn tiến trình gây tốn kém ngữ cảnh (context switch). Nó dùng một vòng lặp sự kiện duy nhất trên mỗi luồng, kết hợp cơ chế kiểm tra sự kiện O(1) (dùng
epollhoặckqueue), giúp phát hiện I/O ngay lập tức dù có hàng chục nghìn kết nối. - Quản lý bộ nhớ siêu tốc (MRU Memory Allocator): Thay vì gọi hàm
malloc()liên tục, HAProxy dùng các Memory Pools cố định theo cơ chế LIFO. Bộ nhớ vừa giải phóng được tái sử dụng ngay khi còn đang sẵn sàng trong CPU cache. - Chuyển tiếp Zero-copy (TCP Splicing): Ở chế độ Layer 4, HAProxy dùng lệnh
splice()để chuyển tiếp gói tin trực tiếp giữa hai socket ngay trong kernel-space, không cần copy lên user-space, giúp đẩy thông lượng lên hàng chục Gbps. - Cây nhị phân và Parser siêu tốc: Sắp xếp timer và thuật toán bằng Elastic Binary Tree (chi phí O(log N)). Bộ phân tích HTTP Header on-the-fly dùng kỹ thuật checkpoint, chỉ mất khoảng 2 micro-giây để đọc xong một request.
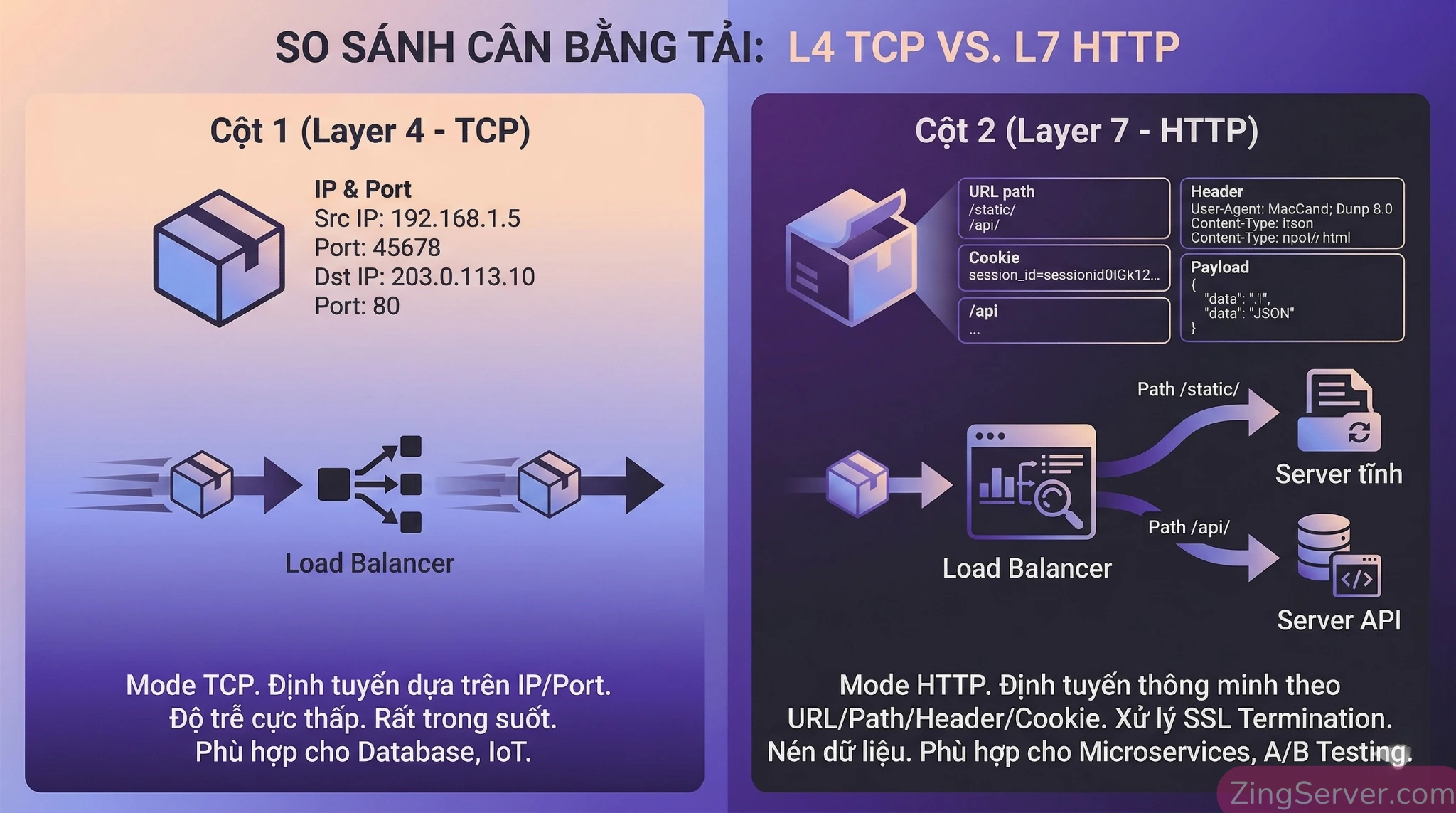
Phân định rạch ròi: Layer 4 (TCP) vs Layer 7 (HTTP)
- Layer 4 (mode tcp): Chỉ nhìn vào IP và Port để định tuyến. Không mở gói tin, không sửa nội dung. Ưu điểm: Tốc độ cực cao, độ trễ cực thấp, tốn ít CPU/RAM. Use case: Database, game server, IoT.
- Layer 7 (mode http): Phân tích sâu vào HTTP header, URL, cookie, payload. Ưu điểm: Định tuyến thông minh theo path, xử lý SSL Termination, thiết lập Sticky Sessions. Use case: Web app phức tạp, Microservices, A/B testing.
Hướng dẫn cấu hình Load Balancer HAProxy chi tiết (thực chiến)
Kiến trúc thực hành: 1 cụm HAProxy (10.0.1.10) đứng trước 3 Web Server (10.0.1.11, 10.0.1.12, 10.0.1.13).
Bước 1: Lựa chọn đúng phiên bản (sai lầm phổ biến nhất)
Theo tài liệu chính thức, HAProxy chia làm hai nhánh rõ rệt:
- Nhánh số chẵn (LTS – Long Term Support) (VD: 2.8, 3.0, 3.2): Hỗ trợ bảo mật lên tới 5 năm. Phù hợp cho môi trường Production doanh nghiệp cần sự ổn định cực cao.
- Nhánh số lẻ (Stable) (VD: 2.9, 3.1, 3.3): Vòng đời cực ngắn (12-18 tháng). Chỉ dành cho early adopters muốn thử nghiệm tính năng mới và sẵn sàng roll-back khi có lỗi.
Quyết định: Luôn cài đặt bản LTS cho chiến dịch Marketing.
Thêm repository của HAProxy 3.2:
sudo add-apt-repository ppa:vbernat/haproxy-3.2 -yCập nhật danh sách gói:
sudo apt updateCài đặt HAProxy:
sudo apt install haproxy -yBước 2: Tối ưu block Global & Defaults (sự thật về NUMA và nbthread)
Mở file /etc/haproxy/haproxy.cfg.
global
log /dev/log local0 info
chroot /var/lib/haproxy
stats socket /var/run/haproxy.sock mode 660 level admin
user haproxy
group haproxy
daemon
master-worker # Bật chế độ tự động hóa Hitless Reload
maxconn 200000
defaults
log global
mode http
option httplog
option redispatch # Tự động chuyển request sang node khác nếu node hiện tại mất kết nối
retries 3
timeout connect 5000ms
timeout client 50000ms
timeout server 60000ms # Cực kỳ quan trọng: Phải dài hơn thời gian API thanh toán xử lý
timeout queue 10000ms
⚠️ CẢNH BÁO KỸ THUẬT: Từ bản HAProxy 3.x, hệ thống tự động phân tích cấu trúc NUMA, L3 Cache và CCX để nhóm các luồng (thread groups) theo vị trí vật lý, giúp tối ưu độ trễ bộ nhớ. Tuyệt đối không tự hardcode tham số nbthread bằng số core CPU. Việc bạn can thiệp thủ công sẽ vô hiệu hóa cơ chế tự động tối ưu này, khiến HAProxy phân bổ tất cả thread vào một nhóm, gây chia sẻ dữ liệu chéo giữa các socket CPU và làm tụt giảm hiệu năng thảm hại.
Bước 3: Block Frontend chặn đứng Bot/DDoS bằng Stick-table
Trong mùa sale, hệ thống thường đối mặt với các công cụ thu thập dữ liệu giá, tự động thêm giỏ hàng số lượng lớn. Cùng với việc cài đặt CrowdSec trên VPS, cấu hình Rate Limiting bằng Stick-table ở tầng Frontend sẽ bảo vệ server của bạn.
frontend https_front
bind *:80
bind *:443 ssl crt /etc/ssl/certs/your_domain.pem alpn h2,http/1.1
http-request redirect scheme https unless { ssl_fc }
# Bảng 1: Dùng GPC0 làm danh sách đen (Blacklist) toàn cầu
stick-table type ip size 1m expire 5m store gpc0
tcp-request connection track-sc0 src
# Từ chối kết nối TẠI TẦNG TCP nếu IP đã bị đánh dấu (gpc0 > 0)
tcp-request connection reject if { sc0_get_gpc0 gt 0 }
default_backend web_cluster
Bí quyết thực chiến: Bằng cách dùng lệnh tcp-request connection reject ở frontend, HAProxy sẽ hủy gói tin ngay tại tầng TCP (Layer 4). Các request bất thường bị ngắt kết nối trước khi kịp tạo thành một HTTP session, không tiêu tốn RAM, không bị ghi log.
Bước 4: Block Backend chọn thuật toán và Health Check sinh tử
backend web_cluster
mode http
balance leastconn # Tối ưu cho hệ thống tải không đồng đều
# Bảng 2: Theo dõi tần suất request thực tế
stick-table type ip size 1m expire 5m store http_req_rate(10s)
acl click_too_fast sc1_http_req_rate gt 10
acl mark_as_abuser sc0_inc_gpc0(http) gt 0
tcp-request content track-sc1 src
tcp-request content reject if click_too_fast mark_as_abuser
# HTTP Check thay vì TCP Check
option httpchk GET /health HTTP/1.1
http-check expect status 200
server web01 10.0.1.11:80 check inter 3000 rise 2 fall 3 maxconn 3000
server web02 10.0.1.12:80 check inter 3000 rise 2 fall 3 maxconn 3000
server web03 10.0.1.13:80 check inter 3000 rise 2 fall 3 maxconn 3000
- Tại sao chọn
leastconn? Với các trang thanh toán (checkout), thời gian xử lý database dài ngắn khác nhau.roundrobin(chia đều xoay vòng) sẽ dồn request vào một máy chủ đang kẹt cứng.leastconnthông minh hơn, luôn đẩy request vào máy chủ đang có ít session hoạt động nhất, ngăn chặn thắt cổ chai cục bộ. - Tại sao dùng
httpchk? Nếu dùng TCP check mặc định, cổng 80 mở là HAProxy báo đang hoạt động. Dù Database ngừng hoạt động, code lỗi trả mã 500, HAProxy vẫn chuyển user vào. Bằng cách gửi requestGET /health(Layer 7), chỉ khi app thực sự hoạt động và trả về HTTP 2xx/3xx, node đó mới được giữ lại.
Nâng cấp vũ khí hạng nặng: Master-Worker và Zero-Downtime Reload
Đang chạy chiến dịch mà cần thêm một máy chủ backend, nếu bạn systemctl restart, hàng nghìn khách hàng đang thanh toán sẽ bị mất kết nối.
Để cấu hình Hitless Reload (Tải lại không gián đoạn), các bài viết cũ thường hướng dẫn dùng cờ expose-fd listeners và truyền file descriptor qua Unix socket (cờ -x). Tuy nhiên, phương pháp chuẩn kỹ sư hiện đại là chạy HAProxy ở chế độ Master-Worker (chỉ thị master-worker trong block global).
Tiến trình Master sẽ quản lý các Worker. Khi cần reload, bạn chỉ việc gửi tín hiệu SIGUSR2 tới Master. Nó sẽ tự động rẽ nhánh (fork) các worker mới (bạn có thể theo dõi realtime tiến trình này nếu đang quản lý log VPS bằng Grafana Loki), truyền file descriptor qua socket nội bộ cực kỳ an toàn mà không rơi rớt một byte dữ liệu nào của user.
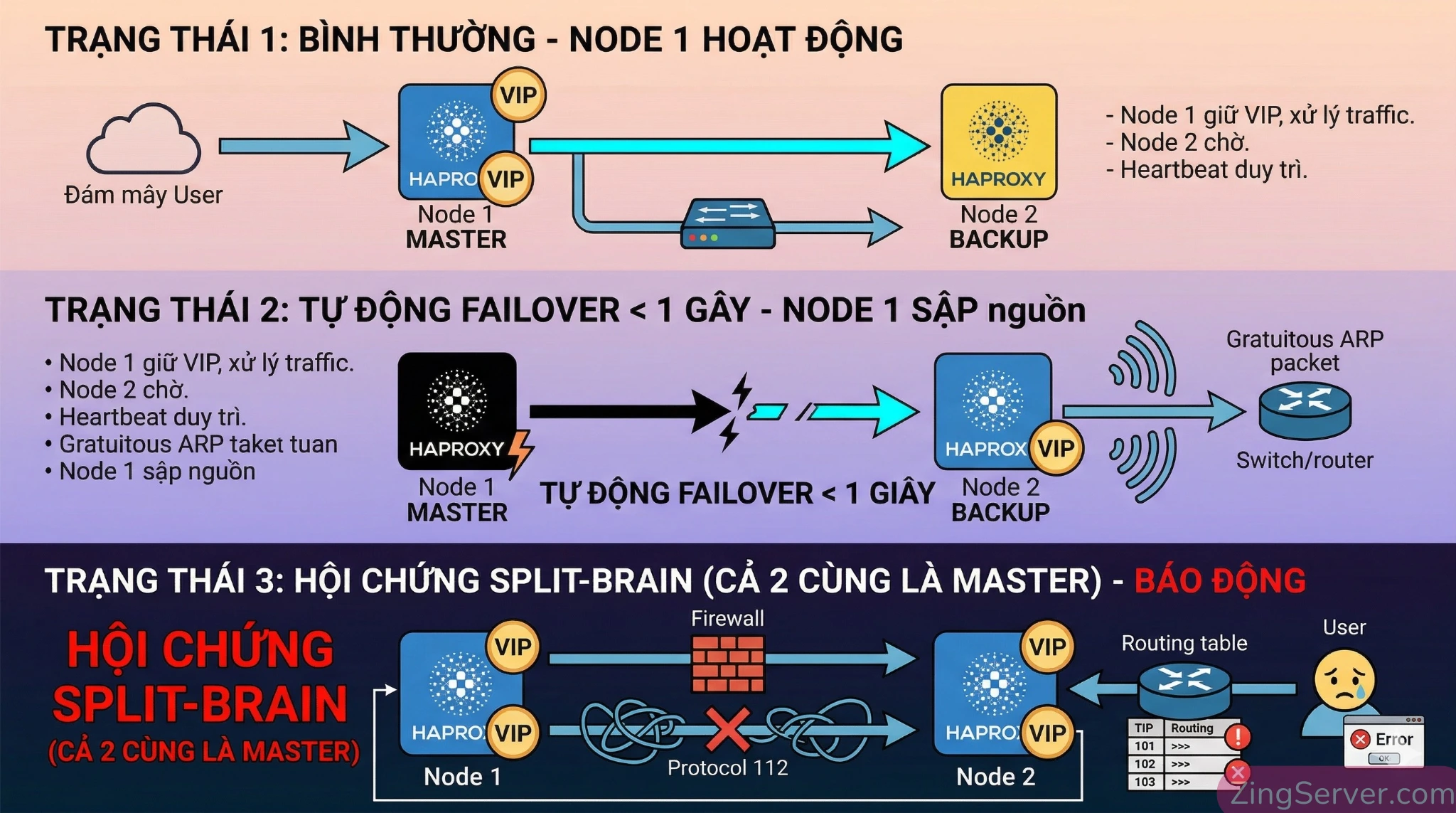
Giữ HAProxy bất tử với Keepalived (tránh thảm họa Split-Brain)
Chạy 2 node HAProxy song song (Active/Passive), Keepalived sẽ dùng giao thức VRRP để cấp IP ảo (VIP). Node Master (priority cao hơn) sẽ liên tục gửi gói tin Heartbeat multicast đến node Backup. Nếu Master mất kết nối, Backup lên thay và gửi gói Gratuitous ARP ra toàn mạng để switch cập nhật lại địa chỉ MAC ngay lập tức.
Lỗi cấu hình nghiêm trọng: Split-Brain! Rất nhiều kỹ sư cấu hình Keepalived xong hệ thống ngừng hoạt động hoàn toàn. Nguyên nhân? Họ quên mở Firewall cho giao thức VRRP (Protocol ID 112). Khi tường lửa chặn Protocol 112, node Backup không nhận được heartbeat, hiểu lầm Master đã mất kết nối nên tự động nâng cấp thành Master và chiếm VIP. Lúc này, cả 2 node cùng tuyên bố sở hữu chung một IP ảo, gây xung đột ARP (ARP conflict) diện rộng, xé nát bảng định tuyến và làm gián đoạn hoàn toàn kết nối. Để phát hiện sớm các dị thường mạng này, việc giám sát VPS bằng Prometheus Grafana là cực kỳ cần thiết.
Giải pháp: Luôn nhớ sudo ufw allow in proto vrrp hoặc cấu hình firewalld tương ứng.
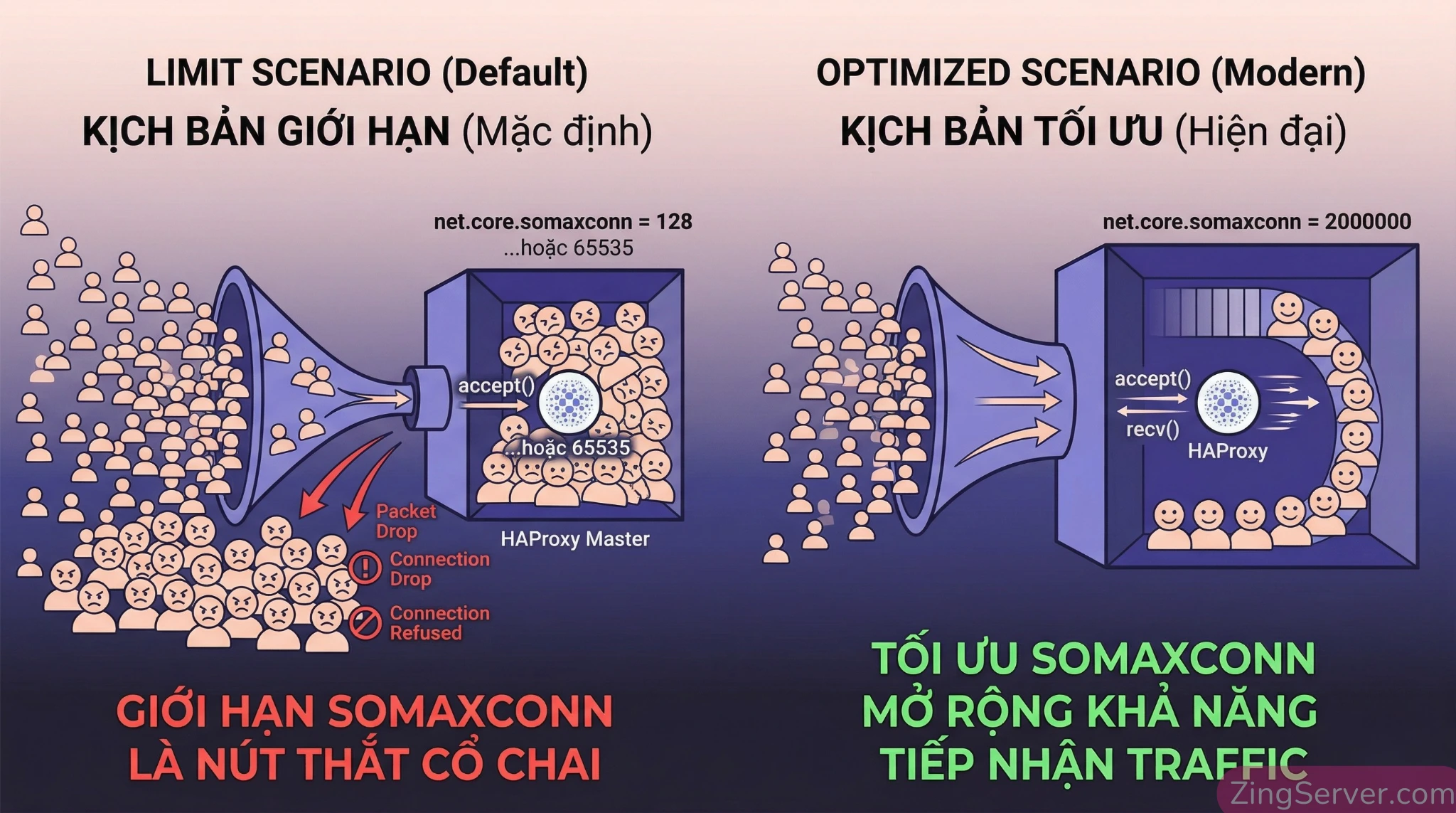
Tinh chỉnh Kernel Linux (Sysctl): giải mã bí ẩn hàng đợi Backlog
HAProxy mạnh đến đâu mà Kernel Linux giới hạn lại thì cũng không đạt hiệu suất tối đa. Cần mở file /etc/sysctl.conf để tinh chỉnh:
# Tái sử dụng socket TIME-WAIT, chống cạn kiệt port
net.ipv4.tcp_tw_reuse = 1
# Nới rộng dải port outbound
net.ipv4.ip_local_port_range = 10000 65000
# Tối ưu hàng đợi backlog
net.ipv4.tcp_max_syn_backlog = 65535
net.core.somaxconn = 65535
net.core.netdev_max_backlog = 65535
# Dọn dẹp kết nối mồ côi nhanh hơn (Mặc định 60s)
net.ipv4.tcp_fin_timeout = 10
# Giữ nguyên tốc độ băng thông sau khoảng nghỉ
net.ipv4.tcp_slow_start_after_idle = 0
Sự thật về tham số net.core.somaxconn: Rất nhiều tài liệu trên mạng định nghĩa sai lệch tham số này là tổng số kết nối tối đa máy chủ chịu được. Thực tế theo tài liệu Linux Kernel, somaxconn chỉ quy định kích thước tối đa của hàng đợi (backlog) chứa các kết nối chưa được ứng dụng accept() trên MỖI socket.
Khi có lượng traffic đột biến ập đến, các kết nối TCP mới sẽ xếp vào hàng đợi này. Nếu hàng đợi đầy, Kernel sẽ drop gói tin.
- Trên các bản Linux cũ (RHEL 6/7), giới hạn hàng đợi này là 16-bit (tối đa
65535). - Trên Linux hiện đại (RHEL 8+, Ubuntu 22+), giới hạn này đã được nâng cấp thành u32 (hơn 2 tỷ). Dù vậy, bạn chỉ cần set
65535hoặc lớn hơn chút đỉnh để hứng trọn burst traffic. Việc cố tình set lên hàng triệu chỉ làm tốn RAM vô ích và che giấu việc backend của bạn đang xử lý quá chậm chạp. Đừng quên chạysysctl -pđể áp dụng.
Câu hỏi thường gặp (FAQ)
1. SPOF là gì và HAProxy giải quyết thế nào?
Điểm đơn lỗi làm ngừng hoạt động toàn hệ thống. HAProxy chia tải ra nhiều server (xóa SPOF backend) và dùng Keepalived tạo cụm dự phòng (xóa SPOF load balancer).
2. HAProxy đạt hiệu suất cao nhờ đâu?
Kiến trúc Event-driven (O(1) checker), Zero-copy (TCP Splicing), và quản lý bộ nhớ MRU giúp xử lý hàng trăm nghìn RPS mà tiêu tốn cực ít RAM.
3. Layer 4 (TCP) khác gì Layer 7 (HTTP)?
L4 định tuyến ở tốc độ cao bằng IP/Port, không mở gói tin. L7 đọc sâu URL, Header, Cookie để điều hướng thông minh và xử lý SSL.
4. Nên dùng bản LTS (số chẵn) hay Stable (số lẻ)?
Luôn dùng LTS (vd: 3.2) cho Production vì hỗ trợ bảo mật 5 năm. Bản số lẻ (vd: 3.3) vòng đời ngắn, chỉ phù hợp để thử nghiệm tính năng mới.
5. Có nên tự set nbthread?
KHÔNG. Từ bản 3.x, HAProxy tự động map thread vào các cụm NUMA. Cấu hình thủ công sẽ phá vỡ cơ chế này, làm giảm hiệu năng.
6. Tại sao leastconn tốt hơn roundrobin mùa Sale?
roundrobin chia đều dễ gây nghẽn cục bộ. leastconn phân bổ traffic vào server đang xử lý ít kết nối nhất, cân bằng tải thực sự hiệu quả.
7. HTTP Check khác gì TCP Check?
TCP chỉ kiểm tra port mở (App lỗi 500 vẫn báo đang hoạt động). HTTP check gọi thẳng vào URL, bắt ứng dụng trả mã 200 mới cho nhận traffic.
8. stick-table bảo vệ hệ thống thế nào?
Lưu IP vào RAM để đánh giá tần suất. Vượt ngưỡng -> Hủy gói tin ngay ở tầng mạng TCP, không tốn RAM duy trì session, không ghi log.
9. Zero-Downtime Reload là gì?
Dùng chế độ master-worker. Gửi tín hiệu SIGUSR2, master tự tạo worker mới và bàn giao file descriptor mượt mà, không gây đứt kết nối.
10. Keepalived VRRP hoạt động ra sao?
Master quản lý IP ảo (VIP) và gửi Heartbeat. Nếu Master mất kết nối -> Backup phát Broadcast (Gratuitous ARP) để tiếp quản VIP trong <1s.
11. Lỗi Split-Brain là gì?
2 node cùng tranh 1 IP ảo làm gián đoạn mạng. Nguyên nhân 99% do quên mở Firewall cho giao thức VRRP (Protocol ID 112).
12. somaxconn có phải là tổng kết nối?
SAI. Nó là giới hạn hàng đợi (backlog) chứa các kết nối TCP đã bắt tay xong nhưng ứng dụng chưa kịp kéo vào xử lý.
13. Giới hạn thực sự của somaxconn?
Linux cũ (RHEL 6/7) giới hạn là 65535 (16-bit). Linux hiện đại dùng chuẩn u32, cho phép hàng đợi lên tới hơn 2 tỷ.
14. Các tham số sysctl nào quan trọng khác?
Bật tcp_tw_reuse (tái sử dụng port), mở rộng ip_local_port_range, tăng tcp_max_syn_backlog và điều chỉnh tcp_fin_timeout xuống 10s.
Kết luận
Bài toán quá tải hệ thống mùa Sale sẽ không còn là rào cản nếu hạ tầng được thiết kế đúng chuẩn kỹ sư. Thông qua việc thấu hiểu cấu hình Load Balancer HAProxy, áp dụng Keepalived chuẩn xác (tránh Split-Brain), và tinh chỉnh cặn kẽ các tham số Kernel Linux, hệ thống của bạn đã sẵn sàng gánh vác hàng triệu luồng traffic phức tạp nhất.





