

2 giờ sáng, tin nhắn từ hệ thống giám sát báo đỏ rực: Production API đang trả về lỗi 500 hàng loạt. Bạn lật đật bật máy tính, mở 5 tab Terminal, bắt đầu SSH vào từng con VPS backend. Gõ tail -f /var/log/nginx/error.log ở tab thứ nhất, không thấy gì. Chuyển sang tab thứ hai, gõ lệnh tương tự. Ở tab thứ ba, bạn phát hiện ổ cứng VPS đã đầy 100% chỉ vì file log của Docker container phình to không kiểm soát, khiến hệ thống OOM (Out of Memory) và ngừng hoạt động.
Đó là một đêm điển hình của những ai đang vận hành hạ tầng phân tán mà thiếu đi một hệ thống Centralized Logging (gom log tập trung).
Nếu bạn đang quản lý từ 2 VPS trở lên, việc theo dấu request và debug lỗi thủ công là một sự lãng phí nguồn lực khủng khiếp. Trong bài viết này, chúng ta sẽ mổ xẻ và triển khai giải pháp quản lý log VPS bằng Grafana Loki, một stack cực kỳ tối ưu, nhẹ nhàng và sinh ra để dành cho các hạ tầng vừa và nhỏ.
Liệu có cách nào gom toàn bộ log rải rác về một Dashboard duy nhất, tránh được cái bẫy chiếm dụng RAM của các hệ thống cũ, và click chuột là tìm ra gốc rễ vấn đề thay vì gõ lệnh mỏi tay? Hãy cùng đi vào thực chiến.


Vòng lặp địa ngục khi truy vết log trên hạ tầng phân tán
Trước khi nói về giải pháp, hãy nhìn thẳng vào những nỗi đau cực kỳ sát sườn mà developer hay sysadmin nào cũng từng nếm trải khi hệ thống bắt đầu scale.
Mở chục tab SSH truy vết log, hoàn toàn mất context
Khi một request đi qua Load Balancer, đập vào Nginx (Reverse Proxy), chui xuống Backend API, và cuối cùng gọi vào Database. Nếu có lỗi xảy ra, log sẽ rải rác ở 4 nơi khác nhau. Việc SSH vào từng máy để grep tìm lỗi giống như tìm những chiếc tất bị thất lạc sau ngày giặt đồ.
Tệ hơn nữa là sự thiếu liên kết (correlation) giữa Metrics và Logs. Metrics giúp bạn biết khi nào (ví dụ: CPU spike lúc 14:05), trong khi Logs cho biết tại sao. Nếu không có một công cụ gom bối cảnh tự động, kỹ sư buộc phải ghi nhớ toàn bộ cấu trúc mạng lưới trong đầu và tự đối chiếu thời gian giữa các hệ thống giám sát khác nhau. Điều này làm chậm trễ nghiêm trọng quá trình tìm ra root cause.
Ổ cứng bốc hơi vì file log Nginx, Docker phình to
File log mặc định của Nginx hay Docker JSON-file driver có thể tăng lên hàng GB chỉ trong vài ngày. Cấu hình mặc định thường ghi lại mọi thứ để phòng hờ, từ lượt truy cập HTTP 200 cho các file tĩnh (static assets) đến các lệnh health check liên tục, tạo ra một lượng dữ liệu rác khổng lồ. Nếu không có chính sách xoay vòng (logrotate), ổ cứng sẽ từ từ bị tiêu tốn sạch. Khi disk full 100%, tiến trình ghi dữ liệu bị chặn đứng, kéo theo sự sụp đổ của toàn bộ dịch vụ.
Trường hợp VPS của bạn đang ngấp nghé bờ vực full disk, hãy xử lý cấp tốc bằng hướng dẫn Cách Extend ổ cứng VPS US, VPS Sing và VPS Việt Nam để cứu vãn hệ thống.
ELK Stack: Dao mổ trâu không dành cho hệ thống nhỏ
Nhiều anh em nghe đến quản lý log là nghĩ ngay đến bộ 3 ELK Stack (Elasticsearch, Logstash, Kibana). ELK cực mạnh, nhưng nó là dao mổ trâu.
Elasticsearch index toàn bộ nội dung của log để tìm kiếm full-text, khiến kích thước file index có thể phình to gấp 1.5 đến 3 lần kích thước log gốc. Dù từ phiên bản 7.11 trở đi, Elasticsearch đã hỗ trợ tự động tính toán JVM Heap Size linh hoạt dựa trên tổng bộ nhớ của node (bạn có thể ép nó chạy ở mức 2GB), nhưng để gánh toàn bộ cụm ELK xử lý log mượt mà trên môi trường production, hệ thống vẫn đòi hỏi CPU tốc độ cao và ổ cứng SSD dung lượng lớn.
Đối với một team startup đang quản lý hạ tầng nhỏ lẻ (vài con VPS 2GB-4GB RAM), việc dành ra một phần lớn tài nguyên chỉ để chạy stack giám sát là bài toán chi phí rất tốn kém.
Tại sao quản lý log VPS bằng Grafana Loki là giải pháp chân ái?
Grafana Loki ra đời để giải quyết chính xác sự cồng kềnh của các hệ thống index toàn văn. Triết lý của Loki rất đơn giản: Log like Prometheus, but for logs.
Triết lý chỉ index label: Bí quyết giúp Loki siêu nhẹ
Điểm làm nên sự khác biệt của Loki là nó không index toàn bộ nội dung của dòng log.
Thay vào đó, Loki chỉ lập chỉ mục một phần rất nhỏ siêu dữ liệu (metadata) được gọi là các label (nhãn) như: host=vps-01, job=nginx, env=production. Nội dung văn bản thực tế của log sẽ được gom lại, nén chặt thành các khối dữ liệu (chunks) và lưu trữ độc lập.
- Lợi ích: Kích thước file index của Loki nhỏ hơn khối lượng log gốc rất nhiều lần. Bằng cách đẩy gánh nặng phân tích văn bản từ thời điểm ghi (ingestion time) sang thời điểm truy vấn (query time), Loki tiêu thụ cực kỳ ít RAM và CPU khi nhận log.
Cạm bẫy High Cardinality (bùng nổ nhãn), lỗi 99% người mới mắc phải
Vì Loki thiết kế để giữ bộ index siêu nhỏ, có một quy tắc sống còn: TUYỆT ĐỐI KHÔNG gắn label cho các giá trị thay đổi liên tục như ip_address, user_id, hay session_id. Nếu bạn làm vậy, hệ thống sẽ dính lỗi High Cardinality (Độ phân mảnh cao). Mỗi IP mới truy cập sẽ sinh ra một luồng log (stream) độc lập. Loki sẽ bị ép phải tạo ra hàng vạn stream, liên tục ghi (flush) hàng ngàn chunk nhỏ chưa được lấp đầy xuống ổ cứng. Điều này làm phình to file index, làm suy giảm hiệu suất truy vấn và có thể làm sập luôn máy chủ Loki.
- Giải pháp: Chỉ dùng nhãn tĩnh (Static labels) như
hosthayapp. Hãy để các dữ liệu động như IP nằm trong văn bản log thô, và dùng sức mạnh của LogQL để rà soát toàn bộ (brute-force scan) khi cần tìm kiếm.
Kiến trúc bộ ba: Promtail, Loki và Grafana (và sự trỗi dậy của Alloy)
Một hệ thống quản lý log VPS bằng Grafana Loki truyền thống sẽ có 3 mảnh ghép:
- Loki Server: Trái tim của hệ thống, nhận, nén, lưu trữ log và xử lý truy vấn.
- Grafana (UI): Giao diện hiển thị, nơi bạn viết LogQL và setup Alert.
- Promtail (Agent): Cài trên các VPS Target. Nó đọc file log, gắn label và push về Loki Server.
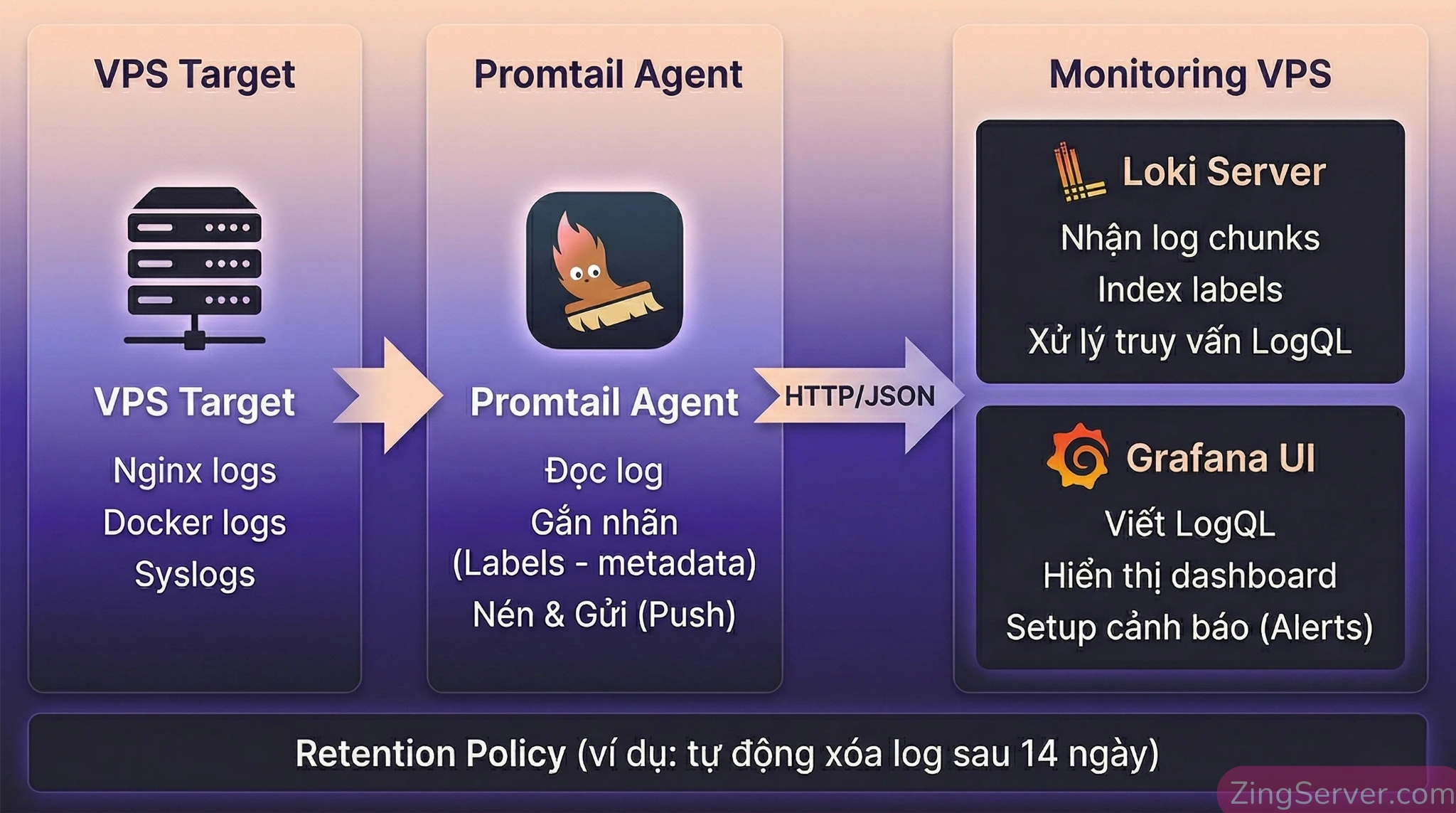
Cập nhật công nghệ: Từ bản phát hành Loki 3.4 (đầu năm 2025), Grafana Labs đã chính thức bắt đầu quá trình hợp nhất (merging) Promtail vào Grafana Alloy (một bản phân phối dựa trên OpenTelemetry Collector) để tạo thành một bộ thu thập duy nhất cho cả log, metrics và traces. Promtail đã End-of-Life (EOL) vào tháng 3/2026. Hiện tại, Alloy đang dần trở thành tiêu chuẩn mới. Trong bài này, chúng ta vẫn sử dụng cấu hình Promtail vì tính đơn giản, nhưng tôi sẽ hướng dẫn bạn cách nâng cấp Alloy bằng một dòng lệnh ở phần cấu hình.
Hướng dẫn cấu hình hệ thống log tập trung trong 20 phút
Chúng ta sẽ setup theo kiến trúc: 01 VPS Server Monitoring (chạy Loki + Grafana) và N VPS Target (cài Agent để đẩy log).
Bước 1: Khởi tạo Loki & Grafana Server bằng Docker Compose
Trên VPS Monitoring, đảm bảo bạn đã cài Docker và Docker Compose.
Lưu ý cấu hình (Rất quan trọng): Dù Loki độc lập rất nhẹ, nhưng để chạy một cụm Monitoring Stack thiết yếu (Grafana + Loki + Prometheus), bạn KHÔNG nên dùng VPS 1GB RAM. Hệ thống sẽ dễ dính OOMKilled do không có không gian dự phòng khi lưu lượng log đột biến. Khuyến nghị tối thiểu: VPS 2 vCPUs, 4GB RAM và 20GB-50GB SSD trống.
Nếu chưa có server đạt chuẩn, bạn có thể tham khảo danh sách TOP VPS nước ngoài, VPS Việt NAM bán chạy nhất để tậu ngay một cỗ máy giám sát khỏe.
Tạo file loki-config.yaml sử dụng TSDB index và bật Compactor để tự động xóa log sau 14 ngày:
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
instance_addr: 127.0.0.1
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
schema_config:
configs:
- from: 2024-01-01
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h # Bắt buộc là 24h để tính năng retention hoạt động
compactor:
working_directory: /tmp/loki/compactor
compaction_interval: 10m
retention_enabled: true
retention_delete_delay: 2h
retention_delete_worker_count: 150
limits_config:
retention_period: 336h # Cấu hình giữ log trong 14 ngày
max_query_lookback: 336hTạo file docker-compose.yml cùng thư mục:
version: "3.8"
services:
loki:
image: grafana/loki:latest
container_name: loki
ports:
- "3100:3100"
command: -config.file=/etc/loki/local-config.yaml
volumes:
- ./loki-config.yaml:/etc/loki/local-config.yaml
- loki_data:/tmp/loki
restart: unless-stopped
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_AUTH_ANONYMOUS_ORG_ROLE=Admin
depends_on:
- loki
restart: unless-stopped
volumes:
loki_data:Khởi chạy cụm server bằng lệnh: docker-compose up -d
Bảo mật sống còn với UFW Firewall
Grafana Loki mặc định không có xác thực trên port 3100. Nếu để public, bất kỳ ai cũng có thể push rác vào làm đầy ổ cứng hoặc đọc trộm log của bạn. Hãy khóa chặt port này và chỉ cho phép VPS Target truy cập bằng UFW:
sudo ufw allow from <IP_CỦA_VPS_TARGET> to any port 3100 proto tcpLưu ý: Để bảo vệ hệ thống của bạn toàn diện hơn trước các luồng truy cập trái phép, hãy cập nhật tư duy thiết lập tường lửa qua bài viết Nâng cấp bảo mật VPS 2026: Tích hợp Zero Trust thay thế phương pháp cũ.
Bước 2: Setup Agent trên các VPS Target để tự động ship log
Trên con VPS đang chạy Web/App (VPS Target), hãy tải Promtail:
Tải file cài đặt Promtail:
curl -fSL -o promtail.zip "https://github.com/grafana/loki/releases/download/v3.6.10/promtail-linux-amd64.zip"Giải nén file vừa tải:
unzip promtail.zipDi chuyển file thực thi vào thư mục hệ thống:
sudo mv promtail-linux-amd64 /usr/local/bin/promtailCấp quyền thực thi:
sudo chmod +x /usr/local/bin/promtailTạo thư mục chứa cấu hình:
sudo mkdir -p /etc/promtailTạo file /etc/promtail/config.yaml để gom log Nginx:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://<IP_CỦA_LOKI_SERVER>:3100/loki/api/v1/push
scrape_configs:
- job_name: nginx_logs
static_configs:
- targets:
- localhost
labels:
job: nginx
env: production
host: vps-target-01 # Tên tĩnh của VPS
__path__: /var/log/nginx/*.logBí kíp nâng cấp Grafana Alloy: Nếu bạn muốn bám sát hệ sinh thái mới nhất của Grafana, bạn không cần viết lại cấu hình từ đầu. Alloy tích hợp sẵn lệnh convert để dịch file của Promtail sang chuẩn .alloy:
alloy convert --source-format=promtail --output=/etc/alloy/config.alloy /etc/promtail/config.yamlBước 3: Cấu hình logrotate trên VPS Target (lưu ý quan trọng)
Chính sách Retention của Loki chỉ xóa log đã được lưu trên Loki Server. Các Agent như Promtail chỉ làm nhiệm vụ đọc chứ không tự xóa file nguồn. Nếu bạn quên bước này, ổ cứng VPS Target vẫn sẽ bị Nginx access log chiếm sạch.
Hãy sửa file /etc/logrotate.d/nginx trên VPS Target:
/var/log/nginx/*.log {
daily
missingok
rotate 3 # Chỉ giữ 3 ngày ở máy local
compress
delaycompress
notifempty
sharedscripts
postrotate
if [ -f /var/run/nginx.pid ]; then
kill -USR1 `cat /var/run/nginx.pid`
fi
endscript
}Lệnh kill -USR1 đảm bảo Nginx mở lại file log mới trơn tru mà không gây downtime.
Trải nghiệm aha moment: Tối ưu debug với LogQL
Truy cập Grafana (http://<IP_LOKI_SERVER>:3000), thêm Data source Loki (http://loki:3100) và mở tab Explore.
LogQL Cheatsheet: Lọc lỗi 5xx thần tốc
Bạn có thể xé nhỏ log và tìm kiếm cực nhanh bằng LogQL:
- Tìm các request lỗi 500 (Rà soát chuỗi thô):
{job="nginx"} |= " 500 " - Loại trừ log nhiễu từ endpoint health check:
{job="nginx"} != "/health" |= " 500 " - Biến log thành Metric để đếm tổng số lỗi mỗi phút:
sum(rate({job="nginx"} != "/health" |= " 500 " [1m]))
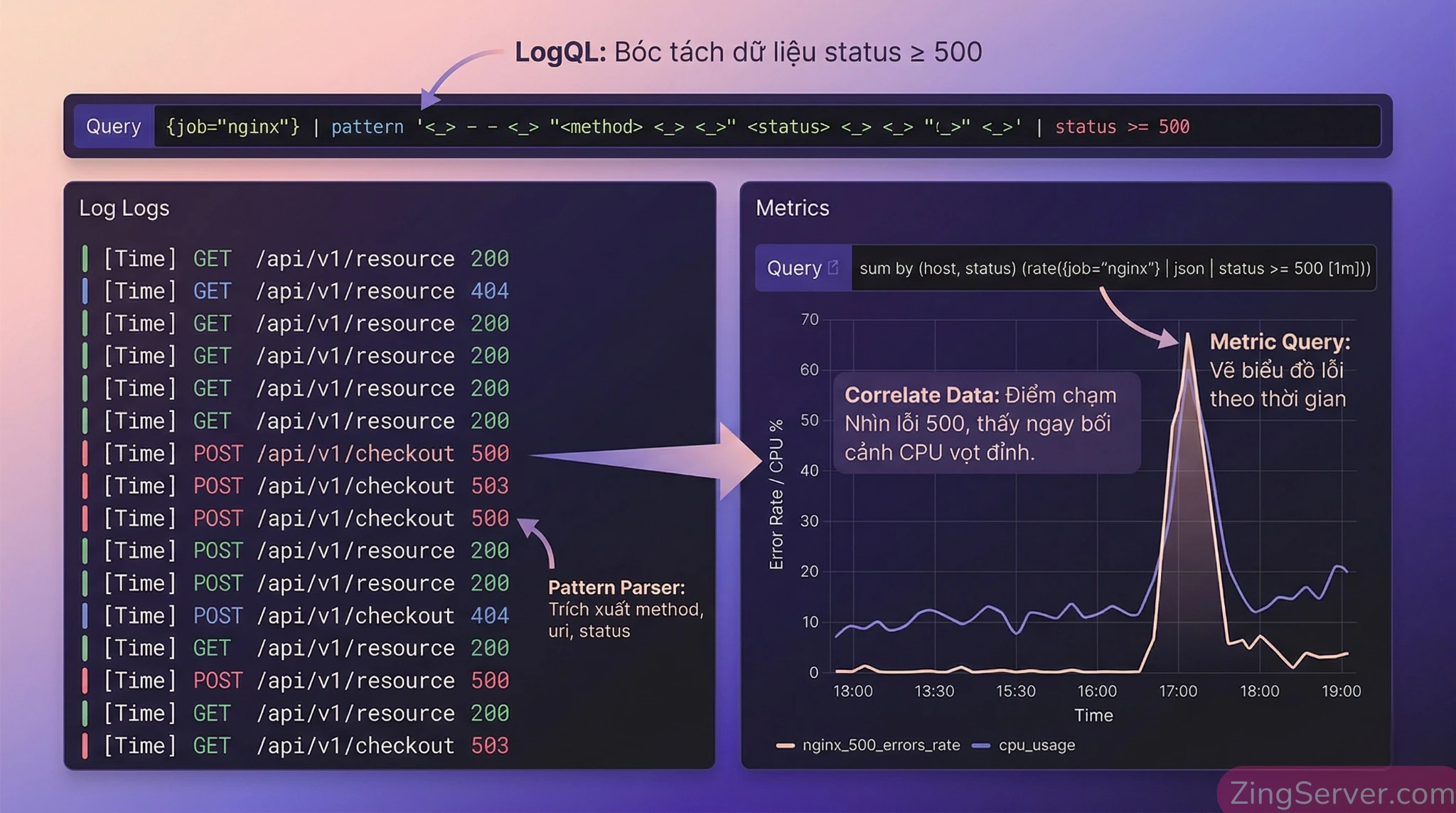
Sức mạnh của Pattern Parser cho Unstructured Logs
Viết Regex để bóc tách log Nginx thô thường là cơn ác mộng. Từ bản Loki 2.3+, tính năng pattern parser cho phép bạn bóc tách dữ liệu nhanh hơn và dễ đọc hơn gấp bội.
Thay vì Regex lằng nhằng, bạn dùng cú pháp bắt giữ vô danh <_> để bỏ qua thông tin rác và chỉ lấy mã trạng thái cùng phương thức HTTP:
{job="nginx"} | pattern '<_> - - <_> "<method> <_> <_>" <status> <_> <_> "<_>" <_>' | status >= 500Correlate Log và Metrics: Điểm chạm WOW của Developer
Điểm mạnh nhất của hệ sinh thái Grafana là khả năng Tương quan dữ liệu (Correlate Data).
Giả sử bạn đang xem biểu đồ Prometheus và thấy CPU của vps-target-01 spike lên 100% lúc 14:05. Thay vì phải tự ghi nhớ thời gian và đổi tool, bạn chỉ cần bôi đen khoảng thời gian đó trên biểu đồ. Nhờ việc dùng chung nhãn (Shared Labels) như host="vps-target-01", Grafana tự động mang bối cảnh thời gian và nhãn này sang truy vấn Loki.
Ngay lập tức, dòng log Nginx lúc 14:05 hiện ra bên dưới, tiết lộ một IP đang spam DDoS vào endpoint /login. Bạn tìm ra root cause trong 10 giây mà không cần mở bất kỳ tab SSH nào!
Scale hệ thống log: Bài toán lưu trữ và tốc độ I/O
Khi hệ thống của bạn mở rộng lên hàng chục VPS, CPU và RAM của Loki Server vẫn chịu tải tốt, nhưng Disk I/O (Tốc độ đọc/ghi ổ đĩa) sẽ trở thành nút thắt cổ chai.
Loki hoạt động như một cỗ máy grep phân tán. Khi bạn truy vấn log của 30 ngày, Loki phải tải hàng vạn chunk dữ liệu từ ổ cứng lên bộ nhớ, giải nén và rà soát từng dòng. Nếu ổ cứng vật lý của bạn đọc chậm, các luồng truy vấn song song sẽ phải xếp hàng chờ, khiến việc truy vấn bị treo (timeout).
Việc cấu hình thủ công cho từng node sẽ rất tốn thời gian, đây là lúc bạn nên áp dụng các kỹ thuật Tự động hóa quản trị VPS: Triển khai Infrastructure as Code (IaC) 2026 để đồng bộ file config Promtail.
Giải pháp lưu trữ phân tầng với Thanos Client
Từ bản Loki 3.4, Grafana đã chuẩn hóa lưu trữ bằng Thanos Object Storage Client, cho phép bạn thiết lập kiến trúc lưu trữ phân tầng (Tiered Storage) hoàn hảo cho môi trường Production:
- Lưu trữ Chunk dài hạn siêu rẻ: Cấu hình đẩy toàn bộ các log chunks đã nén xuống Object Storage (AWS S3, Google Cloud Storage, MinIO). Không gian lưu trữ vô hạn giúp bạn giữ log hàng năm trời phục vụ audit bảo mật mà chi phí chỉ bằng một góc ổ cứng truyền thống.
- Bù đắp độ trễ bằng ổ cứng NVMe: Object Storage lưu rẻ nhưng truy xuất chậm. Để giải quyết nút thắt Disk I/O, hãy thiết lập máy chủ Loki sử dụng ổ cứng NVMe tốc độ cao (hoặc Block Storage chuẩn NVMe) chuyên biệt làm Index và Cache. Băng thông khổng lồ của NVMe sẽ giúp các worker của Loki không phải chờ đợi khi nạp hot data, duy trì tốc độ load trên Grafana tính bằng mili-giây.
Câu hỏi thường gặp (FAQ)
1. Loki có thực sự nhẹ hơn ELK Stack không?
Có. Loki nhẹ hơn hàng chục lần vì nó chỉ đánh chỉ mục (index) các nhãn (labels) như tên server, thay vì phân tích và index toàn bộ nội dung text của dòng log như Elasticsearch.
2. Thuê VPS 1GB RAM để chạy cụm Monitoring (Loki + Grafana + Prometheus) được không?
Không. 1GB RAM sẽ khiến hệ thống bị OOMKilled liên tục do không đủ không gian xử lý lúc lưu lượng log tăng vọt. Bạn cần VPS tối thiểu 4GB RAM và ổ cứng SSD/NVMe để chạy mượt toàn bộ cụm.
3. Đã cấu hình giữ log 14 ngày trên Loki, sao ổ cứng VPS chạy app vẫn bị full?
Vì Agent (Promtail/Alloy) chỉ “đọc và gửi” chứ không có quyền xóa file gốc. Bạn bắt buộc phải cấu hình logrotate trên VPS chạy app để xóa các file log cũ đi.
4. Lỗi High Cardinality (bùng nổ nhãn) trong Loki là gì?
Là lỗi làm sập hoặc làm chậm Loki do bạn gán label bằng các giá trị thay đổi liên tục (như địa chỉ IP, UserID). Chỉ nên dùng label tĩnh (như env=prod), còn tìm IP thì dùng LogQL để lọc thẳng trong nội dung text.
5. Promtail đã End-of-Life (EOL), giờ setup hệ thống mới thì nên dùng Agent nào?
Hãy dùng Grafana Alloy. Đây là bộ thu thập telemetry All-in-one mới nhất của hãng (gom chung cả log, metrics, traces). Bạn có thể dùng lệnh alloy convert để dịch tự động file cấu hình Promtail cũ sang chuẩn mới.
Kết luận
Việc quản lý log VPS bằng Grafana Loki không chỉ là một thủ thuật vận hành, nó là sự nâng cấp tư duy kiến trúc. Bằng cách thiết lập đúng công cụ, tránh bẫy High Cardinality và mạnh dạn trang bị NVMe cho hạ tầng Monitor, bạn sẽ làm chủ hoàn toàn bức tranh dữ liệu của mình. Hệ thống đã scale, cớ sao bạn vẫn còn lọ mọ với lệnh tail -f?
Tài liệu tham khảo
- Grafana Loki 3.4: Standardized storage config, sizing guidance, and Promtail merging into Alloy | Grafana Labs
- How labels in Loki can make log queries faster and easier | Grafana Labs
- New in Loki 2.3: LogQL pattern parser makes it easier to extract data from unstructured logs | Grafana Labs
- Migrate from Promtail to Grafana Alloy | Grafana Alloy documentation
- Elasticsearch heap size usage and JVM garbage collection – Elasticsearch Labs