


2 giờ sáng, CPU của production server vọt lên 100%, RAM overcommit cắn sạch không gian Swap, và tiến trình OOM Killer bắt đầu khai tử các service quan trọng nhất. Giao diện người dùng trả về lỗi 502 Bad Gateway. Khách hàng bắt đầu réo gọi bộ phận CSKH, CEO nhắn tin hối thúc liên tục trên nhóm chat. Trong khi đó, toàn bộ team Dev và Ops vẫn đang chìm trong giấc ngủ vì không hề có một tiếng chuông thông báo nào được gửi đi.
Đã bao giờ hệ thống của bạn rơi vào thảm cảnh này chưa?
Theo báo cáo của Gartner, thiệt hại trung bình cho mỗi phút downtime của hệ thống IT lên tới 5.600 USD/phút. Thậm chí, một nghiên cứu từ Ponemon Institute đã nâng mức trung bình này lên gần 9.000 USD/phút. Việc phó mặc hạ tầng mạng cho nhân phẩm hoặc chỉ phụ thuộc vào các tool check ping cơ bản là một canh bạc quá đắt đỏ. Đó là lý do các Tech Lead hiện nay đều bắt buộc phải xây dựng một hệ thống giám sát VPS bằng Prometheus Grafana chuyên nghiệp, trực quan và tự động.
Hệ thống này không chỉ giúp bạn nhìn thấu mọi ngóc ngách của tài nguyên máy chủ, mà còn đóng vai trò như một còi báo động thông minh, bắn thông báo chủ động trước khi mọi thứ thực sự sụp đổ. Vậy làm thế nào để setup một cụm monitor chuẩn production, không sinh ra cảnh báo rác và scale tốt khi hạ tầng phình to? Cùng đi sâu vào bài viết thực chiến dưới đây.


Chuyển từ chữa cháy sang phòng ngừa: tại sao phải là Prometheus & Grafana?
Nỗi đau muôn thuở của đội ngũ vận hành là sự mù tịt về trạng thái thực tế của hạ tầng. Các giải pháp giám sát truyền thống thường dẫn đến hai vấn đề chí mạng:
- Alert fatigue (Bội thực cảnh báo rác): Hệ thống cũ thường cảnh báo dựa trên triệu chứng (CPU cao) thay vì nguyên nhân hoặc ảnh hưởng thực tế. Việc nhận quá nhiều tiếng ồn (noise) không có ngữ cảnh khiến đội ngũ vận hành sinh ra thói quen phớt lờ thông báo, dễ dàng bỏ qua các sự cố thực sự nghiêm trọng.
- Phản ứng chậm do thiếu ngữ cảnh: Chỉ cho biết Cái gì lỗi chứ không biết Tại sao. Nếu thiếu sự kết hợp dữ liệu đồng bộ, kỹ sư chỉ đang giải quyết phần ngọn dựa trên phỏng đoán (confirmation bias) thay vì nhìn thấu bản chất vấn đề.
Để thấy rõ sự khác biệt, hãy nhìn vào bảng so sánh giữa cách làm cũ (Ping) và cách làm chuẩn Production hiện nay:
| Tiêu chí | Giám sát thụ động (Ping/Uptime Check) | Giám sát chủ động (Prometheus) |
| Cơ chế | Kiểm tra hộp đen từ bên ngoài (Ping, HTTP GET xem có đang hoạt động hay mất kết nối không). | Kéo (Pull) metrics sâu từ bên trong nhân OS & Application. |
| Độ chi tiết | Rất thấp (Chỉ biết có phản hồi hay không). | Rất cao (Nắm rõ CPU steal, RAM cache rò rỉ, I/O Wait, Network Drop). |
| Khả năng dự báo | Bằng 0 (Server mất kết nối hẳn rồi mới báo). | Rất mạnh (Dùng toán học để dự báo Disk đầy trước 6-12 tiếng). |
| Xử lý cảnh báo | Dễ bị spam tin nhắn (Ví dụ rớt mạng 5s báo 1 lần). | Gom nhóm thông minh, loại bỏ trùng lặp qua Alertmanager. |
| Mục đích (Use case) | Phù hợp check Uptime trạng thái bề mặt. | Bắt buộc cho Production, phục vụ điều tra Root Cause (nguyên nhân gốc). |
Sự kết hợp giữa Prometheus và Grafana giải quyết triệt để bài toán này, giúp team Tech chuyển từ thế bị động sang chủ động hoàn toàn.
Trade-off: khi nào không nên dùng Prometheus?
Với tư cách là người làm kỹ thuật, chúng ta cần nhìn nhận khách quan. Không có viên đạn bạc cho mọi bài toán:
- Quy mô quá nhỏ (1-5 VPS) và ngân sách hạn hẹp: Chạy cụm Prometheus + Grafana tốn khoảng 400-600MB RAM và cần một server riêng. Nếu bạn chỉ có vài VPS nhỏ, hãy dùng các Lightweight Tools như Beszel, Uptime Kuma hoặc đẩy data lên Grafana Cloud Free Tier.
- Cần độ chính xác 100% cho Billing: Prometheus dùng cơ chế lấy mẫu (sampling). Nếu bạn cần đếm chính xác từng request để tính tiền khách hàng, hãy dùng hệ thống Event-logging thay vì Prometheus.
Kiến trúc luồng dữ liệu (Architecture Flow) 4 lớp hoàn hảo
Để hiểu tại sao stack này là tiêu chuẩn vàng, bạn cần nắm rõ luồng dữ liệu 4 lớp phối hợp chặt chẽ:
- Lớp thu thập (Node Exporter): Một ứng dụng siêu nhẹ chạy trên các VPS mục tiêu. Nhiệm vụ của nó là đọc chỉ số phần cứng (CPU, RAM, Disk, Network) và phơi bày (expose) chúng ra một cổng kết nối (thường là 9100).
- Lớp lưu trữ & đánh giá (Prometheus Server): Đây là bộ não. Thay vì đợi server gửi dữ liệu (Push), Prometheus dùng cơ chế Pull (Kéo dữ liệu). Cứ mỗi 15 giây, nó chủ động chọc vào Node Exporter để kéo metric về lưu vào Time-series database.
- Ưu điểm của Pull: Tích hợp sẵn Health Check. Prometheus tự sinh ra metric
up(1 là đang hoạt động, 0 là mất kết nối). Nếu dùng Push, bạn không thể biết server đã ngừng hoạt động hay chỉ đơn giản là đang không có dữ liệu để gửi.
- Ưu điểm của Pull: Tích hợp sẵn Health Check. Prometheus tự sinh ra metric
- Lớp quản lý cảnh báo (Alertmanager): Nhận cảnh báo từ Prometheus. Thay vì gửi đi ngay, nó xử lý chuyên sâu: loại bỏ trùng lặp, gom nhóm (grouping) và điều hướng (routing) tới Telegram/Slack.
- Lớp hiển thị trực quan (Grafana): Kết nối với Prometheus, dùng ngôn ngữ PromQL biến dữ liệu khô khan thành các Dashboard cực kỳ trực quan.
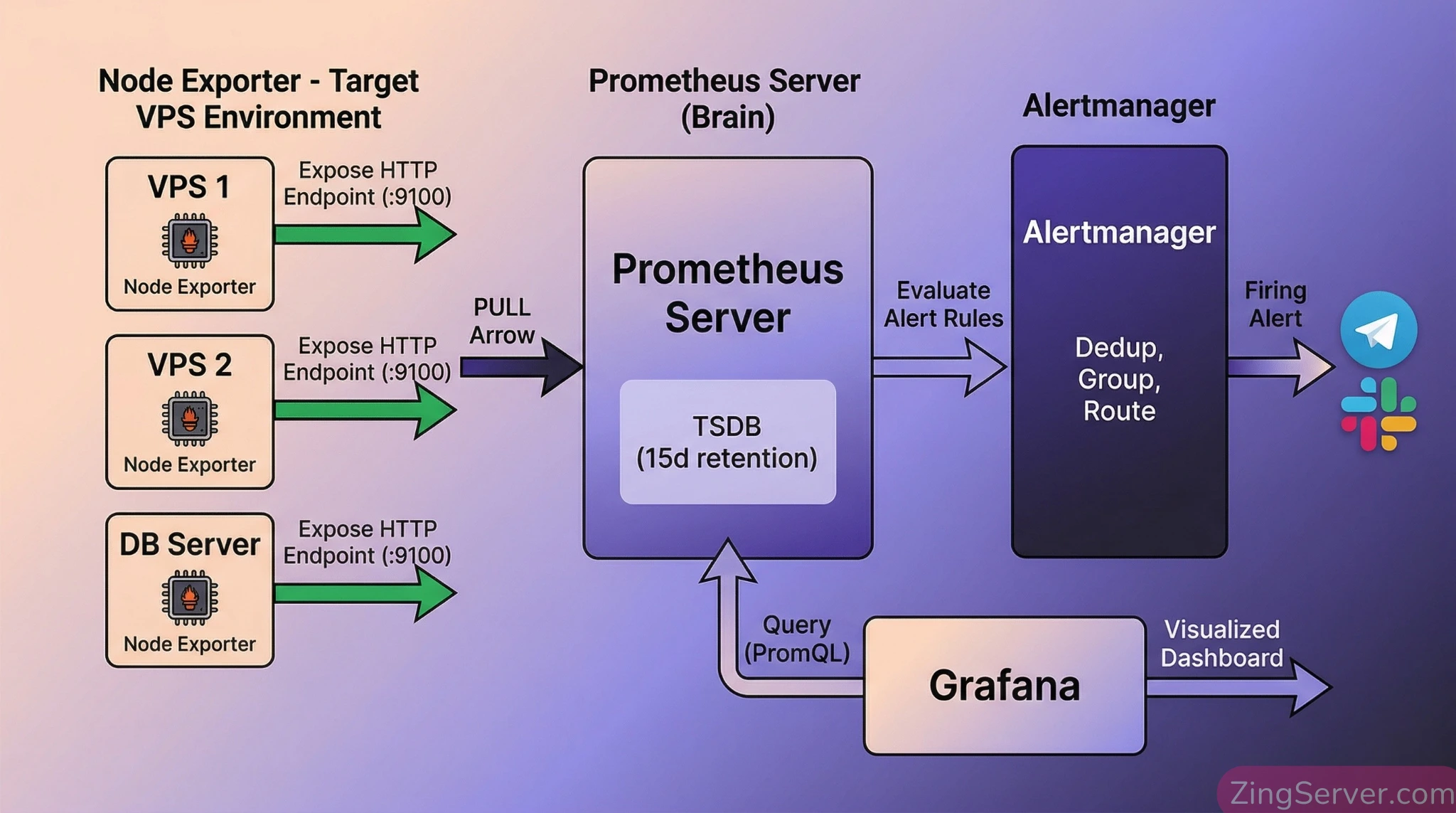
Hướng dẫn setup hệ thống giám sát VPS bằng Prometheus Grafana (chuẩn Production)
Để đảm bảo an toàn, cụm bộ não (Prometheus, Grafana, Alertmanager) phải được đặt trên một VPS Monitor riêng biệt thông qua Docker Compose. Còn trên các VPS cần giám sát (Target), ta chạy Node Exporter dưới dạng Systemd service.
Cách tổ chức file cấu hình này cũng là bước đệm hoàn hảo nếu team bạn đang hướng tới việc triển khai Infrastructure as Code (IaC).
Bước 1: Gắn cảm biến Node Exporter lên các VPS mục tiêu
Truy cập vào các VPS chạy ứng dụng và thực hiện script Bash tự động sau. Script này tải bản v1.10.2, tạo user hệ thống (không có quyền login shell để bảo mật) và setup systemd.
#!/bin/bash
set -e
VERSION="1.10.2"
ARCH="linux-amd64"
DOWNLOAD_URL="https://github.com/prometheus/node_exporter/releases/download/v${VERSION}/node_exporter-${VERSION}.${ARCH}.tar.gz"
echo "Đang tải Node Exporter v${VERSION}..."
wget -q $DOWNLOAD_URL -O /tmp/node_exporter.tar.gz
tar xvfz /tmp/node_exporter.tar.gz -C /tmp/
sudo mv /tmp/node_exporter-${VERSION}.${ARCH}/node_exporter /usr/local/bin/
rm -rf /tmp/node_exporter-${VERSION}.${ARCH} /tmp/node_exporter.tar.gz
# Tạo user hệ thống không có quyền login shell
if ! id "node_exporter" >/dev/null; then
sudo useradd -rs /bin/false node_exporter
fi
# Cấu hình systemd service
sudo tee /etc/systemd/system/node_exporter.service > /dev/null <<EOF
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable --now node_exporter
echo "Cài đặt thành công! Node Exporter đang chạy trên port 9100."🚨 Security Tip cực kỳ quan trọng: Mặc định, Node Exporter expose dữ liệu ra port 9100 dưới dạng clear text. Ngoài việc rò rỉ các thông tin nhạy cảm, port này còn bật sẵn giao diện gỡ lỗi của Go (/debug/pprof). Kẻ tấn công có thể gửi hàng loạt request vào endpoint này để ép CPU thực hiện profiling, gây cạn kiệt tài nguyên và dẫn đến tấn công DoS (Từ chối dịch vụ).
TUYỆT ĐỐI KHÔNG mở toang port 9100 ra Internet. Bạn cần đổi mật khẩu VPS Linux để bảo vệ quyền root, sau đó dùng UFW chặn mọi truy cập, chỉ cho phép đúng IP của máy chủ Monitor đi vào.
Thay <IP_MAY_CHU_MONITOR> bằng IP tĩnh của con VPS cài Prometheus:
sudo ufw allow from <IP_MAY_CHU_MONITOR> to any port 9100 proto tcpXóa luật allow all cũ nếu có:
sudo ufw delete allow 9100/tcpNếu bạn quản trị hạ tầng phân tán phức tạp, hãy tham khảo thêm chiến lược tích hợp Zero Trust thay thế phương pháp cũ để thiết lập các đường hầm bảo mật mã hóa thay vì chỉ dựa vào IP.
Bước 2: Dựng bộ não Prometheus Server bằng Docker Compose
Trên VPS Monitor, tạo file docker-compose.yml:
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: unless-stopped
ports:
- "9090:9090"
volumes:
- ./prometheus:/etc/prometheus
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention.time=15d' # Khai báo tường minh thời gian lưu trữ
- '--web.enable-lifecycle' # Cho phép reload config không cần restart
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
restart: unless-stopped
ports:
- "9093:9093"
volumes:
- ./alertmanager:/etc/alertmanager
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: unless-stopped
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=OpsAdmin@2026
volumes:
prometheus_data:
grafana_data:Tại sao cần khai báo tường minh 2 cờ lệnh trên?
--storage.tsdb.retention.time=15d: Dù 15 ngày là mặc định của Prometheus, việc ghi rõ giúp team dễ dàng quy hoạch dung lượng (Capacity Planning). Tùy dung lượng ổ cứng, bạn có thể chủ động hạ xuống7dhoặc tăng lên30d.--web.enable-lifecycle: Mở endpoint/-/reload. Khi bạn thêm một VPS mới vào file config, chỉ cần gọi API reload mà không cần khởi động lại container (Zero-downtime), tránh làm gián đoạn luồng dữ liệu.
Tiếp theo, tạo file prometheus/prometheus.yml:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'node_exporter'
static_configs:
- targets:
- '14.xxx.yyy.100:9100' # IP của VPS TargetLưu ý: Tài liệu chính thức quy định scrape_interval mặc định là 1 phút (1m). Tuy nhiên, trong thực chiến, ta ép xuống 15s để bắt trọn các đợt tăng tải ngắn hạn (short-lived spikes) và có độ phân giải dữ liệu tốt nhất khi xử lý sự cố.
Chạy lệnh docker-compose up -d để khởi động cụm.
Bước 3: Trực quan hóa với Grafana & import Dashboard thần thánh
Truy cập http://<IP_Monitor>:3000. Sau khi Add Data Source là Prometheus (http://prometheus:9090), bạn không cần tự vẽ biểu đồ thủ công.
Vào Dashboards -> Import, nhập ID 1860 (Node Exporter Full) và Load.
Chỉ mất đúng 3 giây, bạn đã có một buồng lái cực ngầu hiển thị toàn bộ thông số: CPU, RAM, Disk I/O, Network Bandwidth của toàn bộ hệ thống.
Alertmanager: còi báo động tự động réo tên Dev qua Telegram/Slack
Dashboard đẹp đến mấy cũng vô nghĩa nếu không ai nhìn vào nó lúc 2 giờ sáng. Alertmanager chính là lớp bảo vệ chủ động.
Các PromQL chí mạng Tech Lead cần cấu hình ngay
Trong file alert_rules.yml, hãy định nghĩa các biểu thức (expr) PromQL sau:
1. Bắt lỗi sập nguồn (InstanceDown):
expr: up == 0Nếu mất kết nối mạng hoặc server ngừng hoạt động, metric up sẽ về 0.
2. Cảnh báo CPU vượt 85% trong 5 phút:
expr: 100 * (1 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]))) > 85
for: 5mLấy 100% trừ đi tốc độ gia tăng trung bình của thời gian rảnh (idle) trên tất cả các core. Nếu vượt 85% liên tục trong 5 phút, báo động đỏ.
3. Cảnh báo RAM vượt ngưỡng 90%:
expr: 100 * (1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) > 904. PRO TIP: Dự báo ổ cứng (Disk) đầy trong 6 giờ tới:
expr: predict_linear(node_filesystem_avail_bytes{fstype!~"tmpfs|nsfs"}[1h], 21600) <= 0Thay vì cảnh báo khi ổ cứng đã đầy 100% (lúc này bạn không thể SSH vào để sửa), hàm predict_linear() sử dụng hồi quy tuyến tính. Nó nhìn vào tốc độ ghi file log trong 1 giờ qua ([1h]) và dự báo xem trong 21.600 giây (6 tiếng) nữa, dung lượng trống có chạm mức <= 0 hay không. Bạn sẽ có đúng 6 tiếng thảnh thơi dọn rác trước khi sự cố thực sự xảy ra!
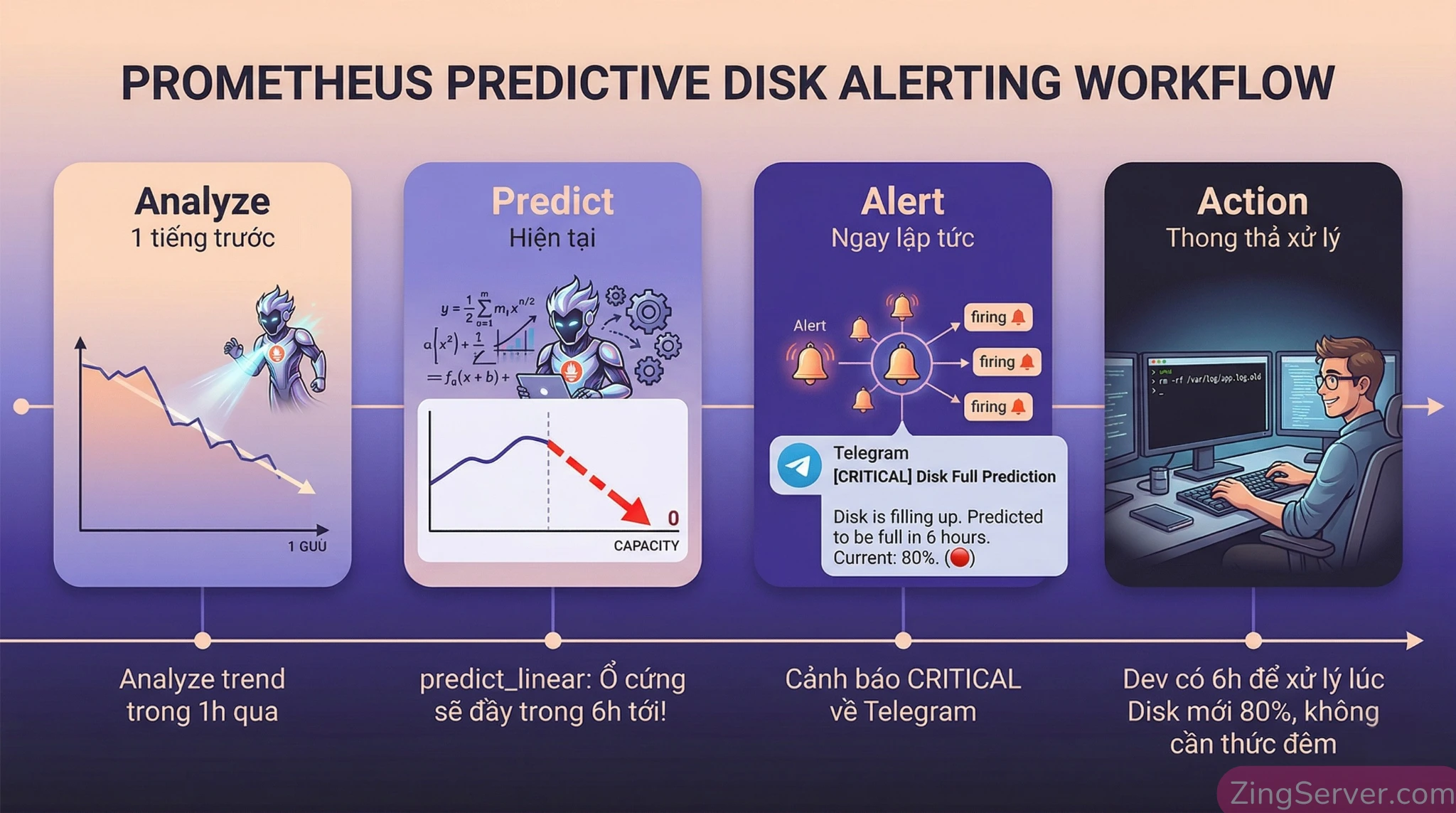
Routing & grouping: chữa dứt điểm bệnh Alert fatigue
Cấu hình alertmanager.yml để định tuyến qua Telegram:
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'instance']
group_wait: 30s
group_interval: 5m
receiver: 'telegram_bot'
receivers:
- name: 'telegram_bot'
telegram_configs:
- bot_token: '<YOUR_BOT_TOKEN>'
chat_id: <YOUR_CHAT_ID>Chống spam tin nhắn: Nếu đứt cáp mạng làm 20 con VPS cùng ngừng hoạt động, group_wait: 30s sẽ kìm lại 30 giây để gom cả 20 lỗi này vào 1 tin nhắn duy nhất thay vì khủng bố điện thoại của bạn 20 lần. Sau đó, group_interval: 5m đảm bảo 5 phút sau mới gửi báo cáo cập nhật tiếp theo.
Tối ưu Alert Template bằng Go Template (thay vì JSON thô)
Việc gửi JSON thô (raw JSON) chứa metadata lộn xộn sẽ khiến Dev hoa mắt. Hơn nữa, Telegram giới hạn 4096 ký tự/tin nhắn. Nếu Alertmanager gom nhóm quá nhiều lỗi, chuỗi JSON dài sẽ bị API từ chối (400 Bad Request) và tin nhắn bị rớt hoàn toàn.
Hãy dùng Go Template để custom lại giao diện: chèn Emoji 🚨 ⚠️, in đậm tên Server, và hiển thị rõ ràng thông số. Tin nhắn đẹp, dễ đọc giúp Dev bắt bệnh nhanh hơn, giảm hẳn thời gian MTTR.
Checklist vận hành & Best Practices để hệ thống Monitor không chết yểu
Để vận hành cụm giám sát ổn định ở mức Production, Tech Lead hãy ghim ngay 2 nguyên tắc sau:
- Monitor the Monitor (Giám sát kẻ giám sát): Đừng để VPS Prometheus trở thành Điểm lỗi duy nhất (Single Point of Failure). Nếu con VPS Monitor ngừng hoạt động, nó không thể tự gửi cảnh báo Tôi đã mất kết nối. Hãy dùng một tool SaaS bên ngoài (như UptimeRobot) liên tục check ping vào cổng 3000 của Grafana để đảm bảo hệ thống giám sát của bạn luôn sống.
- Đính kèm
runbook_url(Actionable Alerts): Đừng chỉ ném một cái mã lỗi vào mặt Dev lúc nửa đêm. Trong cấu hình Alert, hãy chèn link dẫn tới file Docs/Notion nội bộ (Runbook). Khi nhận cảnh báo High RAM, Dev chỉ cần bấm vào link là thấy ngay các câu lệnh Linux cần gõ để clear cache. Điều này giúp giảm MTTR cực kỳ hiệu quả.
Câu hỏi thường gặp (FAQ)
1. Chạy Node Exporter có làm chậm server không?
Không. Tiến trình này viết bằng Go nên siêu nhẹ. Chỉ ngốn ~10-20MB RAM và <1% CPU, hoàn toàn không ảnh hưởng đến ứng dụng chính.
2. Dùng bộ tool này để giám sát VPS Windows được không?
Được. Chỉ cần đổi sang cài windows_exporter trên máy Windows, Prometheus vẫn kéo data bình thường. Sau đó lên Grafana import Dashboard ID 14510 là xong.
3. Prometheus lưu dữ liệu trong bao lâu?
Mặc định 15 ngày. Mục đích của Prometheus là xử lý sự cố nóng (real-time). Nếu muốn lưu theo năm để làm Report/Billing, bạn cần gắn thêm Thanos hoặc Cortex để đẩy data lên S3.
Kết luận
Chuyển đổi từ mô hình chờ khách hàng phàn nàn rồi mới đi tìm lỗi sang mô hình phòng ngự chủ động là cột mốc trưởng thành của bất kỳ team Tech nào. Setup giám sát VPS bằng Prometheus Grafana không chỉ cứu vãn hàng nghìn đô la chi phí downtime, mà còn bảo vệ chất lượng giấc ngủ của anh em kỹ sư.
Tuy nhiên, Prometheus mới chỉ giải quyết bài toán Metrics (Thống kê chỉ số). Khi CPU tăng vọt, Prometheus cho bạn biết Khi nào, nhưng để biết chính xác Dòng code nào gây ra, bạn cần một hệ thống quản lý Logs.
Đó là lúc mảnh ghép Grafana Loki xuất hiện. Lấy cảm hứng từ chính Prometheus, Loki dùng chung một bộ nhãn (Labels) và có ngôn ngữ LogQL tương đồng với PromQL. Nhờ đó, bạn có thể đối chiếu chéo (correlate) từ biểu đồ CPU đang đỏ rực nhảy thẳng sang dòng Log báo Exception tại cùng một thời điểm, trên cùng một giao diện Grafana duy nhất.